





I. Introduction▲
Lors d'une campagne de test de charge et de performance, ou d'une mise en place de supervision de la production, nous sommes amenés à mettre en place des outils de monitoring qui peuvent rapidement être intrusifs.
Le problème est que lorsqu'on mesure un système, on change le contexte de celui-ci et les mesures prises peuvent être faussées.
Pour éviter cela, il faut que les mesures perturbent le moins possible le système mesuré.
Dans cet article nous allons nous concentrer sur la mesure et la répartition de la consommation processeur d'un programme Java. Cela nous permettra de comparer plusieurs outils et de trouver des solutions afin de limiter le problème d'overhead.
II. Différentes méthodes de mesure▲
Il existe plusieurs méthodes permettant de mesurer la consommation processeur d'un programme.
Les deux principales méthodes sont l'échantillonnage et l'instrumentation avec pour chacune des avantages et des inconvénients.
II-A. Échantillonnage▲
L'échantillonnage consiste à récupérer périodiquement la stack des threads en cours d'exécution.
De par sa nature périodique, les mesures sont moins précises (des méthodes Java très rapides peuvent n'être invoquées qu'entre deux intervalles de mesure et donc ne pas apparaitre).
En contrepartie, l'overhead dépend moins de l'application cible et est souvent plus bas (à moins de définir un intervalle de mesure trop faible).
II-B. Instrumentation▲
L'instrumentation consiste à instrumenter le bytecode de chaque méthode afin de récupérer leur consommation processeur.
Grâce à cela, on pourra avoir le nombre d'invocations des méthodes et des mesures plus précises.
Malheureusement, cela peut engendrer un overhead beaucoup plus important.
II-C. Autres méthodes▲
D'autres méthodes peuvent exister (échantillonnage asynchrone, échantillonnage intelligent…) dans les logiciels testés.
III. En quoi la supervision peut-elle fausser les résultats ?▲
Maintenant que nous avons étudié comment est mesurée la consommation CPU par méthode dans un programme Java, regardons pourquoi cela est gênant.
III-A. Utilisation des caches CPU▲
Si l'on regarde l'architecture d'un processeur récent, on voit qu'il y a plusieurs types de cache (L1, L2, L3) afin d'accélérer le traitement des données en y mettant celles qui sont les plus utilisées.
Ces caches vont être plus ou moins rapides, proches des cœurs du processeur et grands.
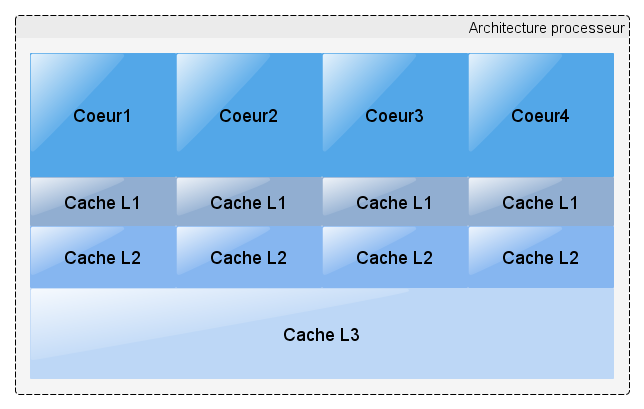
Le cache L1 étant le plus rapide, mais aussi le plus petit, permet d'avoir les meilleures performances.
Malheureusement, sa taille n'est pas extensible à l'infini et donc lors d'un monitoring, le cache risque d'être pollué par des données du monitoring et non de l'application. Les données de l'application n'étant plus dans le cache, elles s'exécuteront plus lentement.
Comme on peut le voir ici, il y a vraiment une différence entre le cache L1 et le reste.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
L1 cache reference ......................... 0.5 ns
Branch mispredict ............................ 5 ns
L2 cache reference ........................... 7 ns
Mutex lock/unlock ........................... 25 ns
Main memory reference ...................... 100 ns
Send 2K bytes over 1 Gbps network ....... 20,000 ns = 20 µs
SSD random read ........................ 150,000 ns = 150 µs
Read 1 MB sequentially from memory ..... 250,000 ns = 250 µs
Round trip within same datacenter ...... 500,000 ns = 0.5 ms
Read 1 MB sequentially from SSD* ..... 1,000,000 ns = 1 ms
Disk seek ........................... 10,000,000 ns = 10 ms
Read 1 MB sequentially from disk .... 20,000,000 ns = 20 ms
Send packet CA->Netherlands->CA .... 150,000,000 ns = 150 ms
Un moyen simple de voir l'impact de la supervision sur le cache L1 de notre CPU est d'utiliser l'outil perf livré avec Linux.
Lançons un test de charge avec JMeter sur une application Web.
Utilisons l'outil perf.
2.
3.
4.
5.
6.
7.
8.
perf stat -e L1-dcache-loads:u -e L1-dcache-misses:u -p 2663
Performance counter stats for process id '2663':
761 655 011 373 L1-dcache-loads:u
29 016 873 504 L1-dcache-misses:u # 3,81% of all L1-dcache hits
607,562500818 seconds time elapsed
Faisons la même chose, mais avec la supervision active.
2.
3.
4.
5.
6.
7.
8.
perf stat -e L1-dcache-loads:u -e L1-dcache-misses:u -p 22798
Performance counter stats for process id '22798':
151 471 959 217 L1-dcache-loads:u
6 881 372 123 L1-dcache-misses:u # 4,54% of all L1-dcache hits
598,713042437 seconds time elapsed
Comme on peut le voir, lorsque la supervision est active, l'utilisation des caches L1 est beaucoup moins performante (moins de données chargées en cache, Cache Miss Ratio plus grand).
III-B. JIT (Just In Time)▲
Depuis un certain nombre de versions, la JVM incorpore un compilateur JIT (Just In Time) qui permet de transformer du bytecode en code optimisé.
De nombreuses optimisations existent (inlining, élimination de code mort…) et permettent d'accélérer les performances de l'application.
Toutes ces optimisations sont faites de manière dynamique à l'aide des informations de fonctionnement de l'application.
Or l'ajout de code par instrumentation va perturber le compilateur JIT et peut dans certains cas empêcher une optimisation.
Par exemple, le fait de rendre une méthode inline dépend en partie de sa taille et donc l'ajout d'instructions peut empêcher cette optimisation pour certaines d'elles et donc modifier le comportement de la JVM.
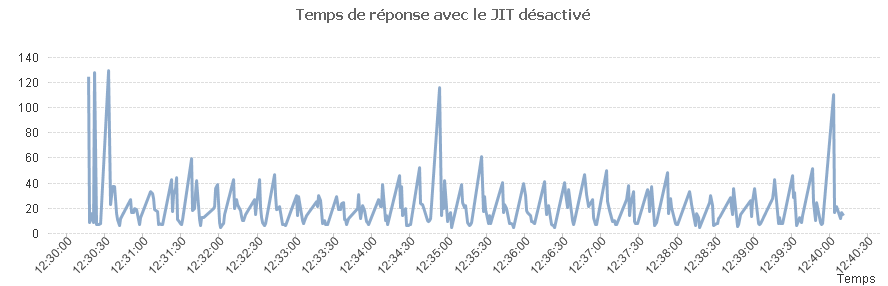
Afin de mettre en évidence la perte de performance dans le cas où le JIT ne peut pas optimiser le code, nous allons faire un test avec le JIT activé puis le JIT désactivé (option -Xint).
Lorsque je JIT est désactivé on a.
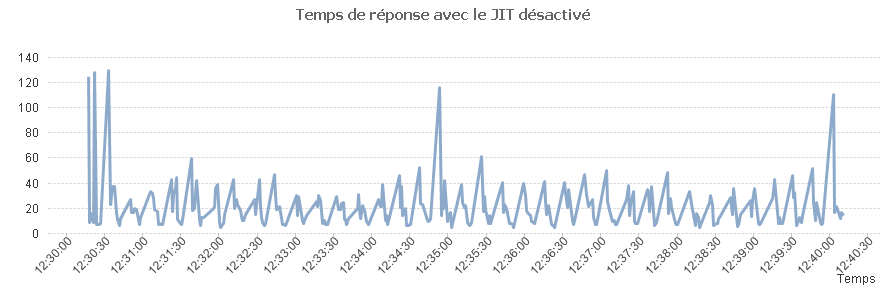

Et avec le JIT activé on a.
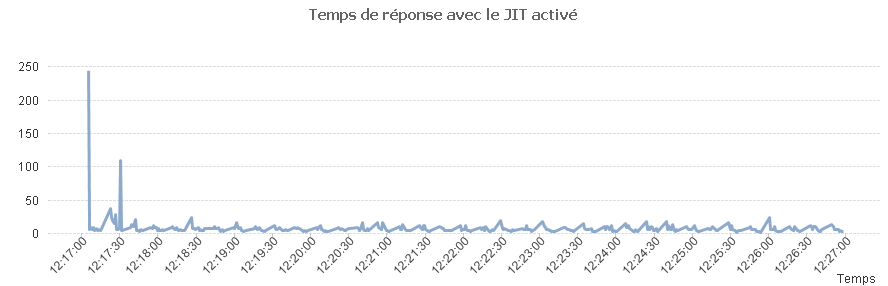

Les résultats se passent de commentaires.
III-C. Consommation mémoire▲
Pour comprendre tous les effets négatifs sur la consommation mémoire, on va réviser le fonctionnement d'une JVM générationnelle.
De manière simplifiée, l'architecture mémoire d'une JVM générationnelle ressemble à :

Le principe du fonctionnement du GC est le suivant (attention dans certains cas particuliers, ce n'est pas ce fonctionnement qui est utilisé).
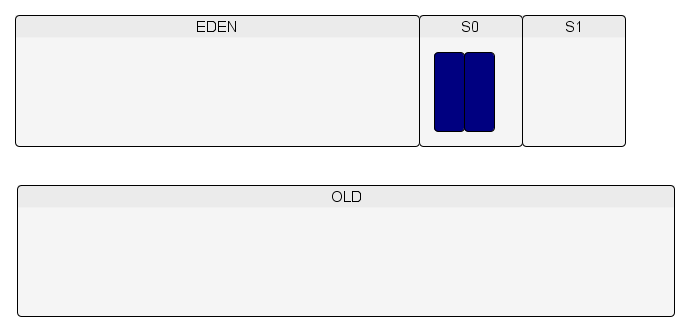
Les objets sont créés dans l'espace Eden.
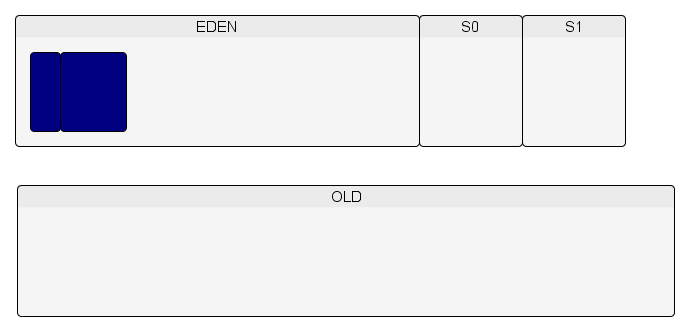
Lorsque l'espace Eden est plein et/ou a atteint un certain pourcentage de remplissage, un minor GC est exécuté.

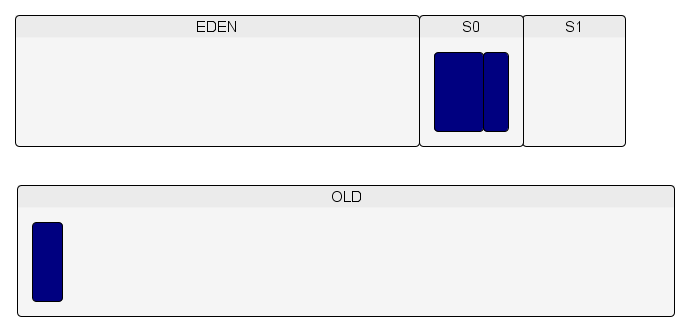
Lors de ce minor GC, les objets encore vivants dans l'Eden sont copiés dans l'espace S0.
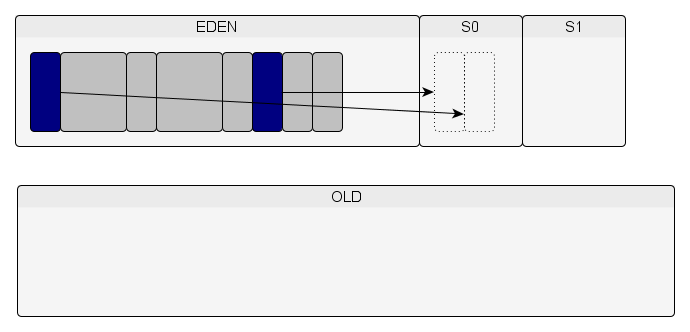
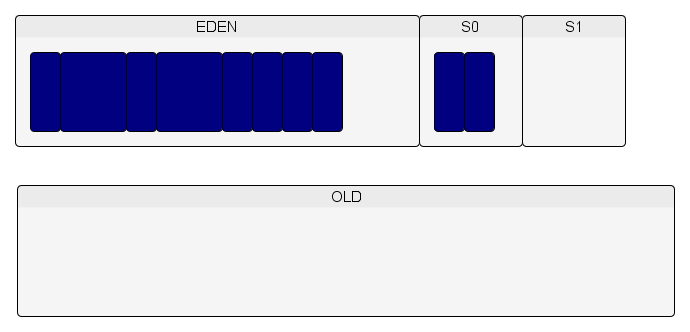
De nouveaux objets sont créés dans l'Eden et un autre minor GC est exécuté lorsqu'il n'y a plus de place dans l'Eden.
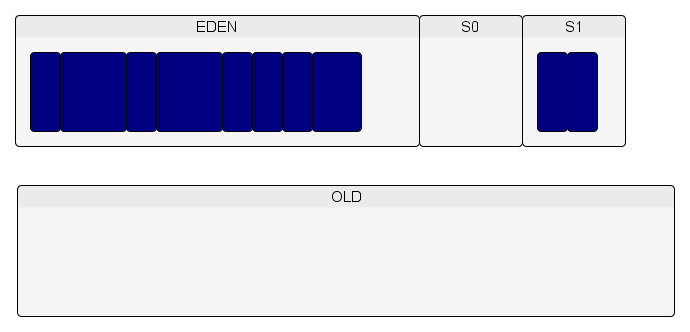
Le minor GC copie les objets encore vivants de l'Eden et de S0 en S1.
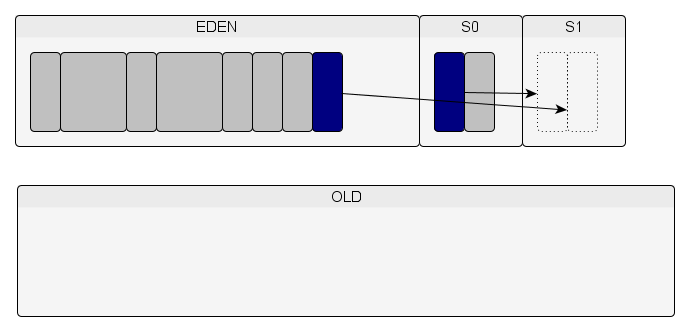
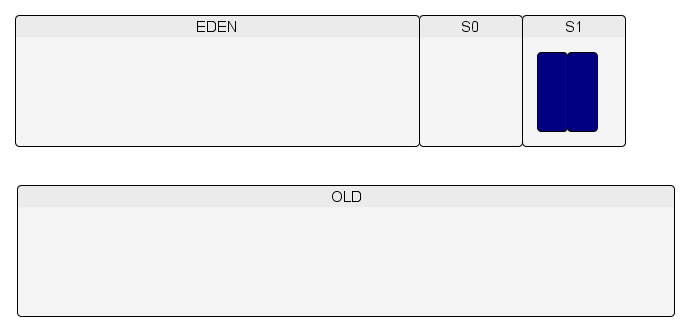
On recommence (création d'objets dans l'Eden…).
Un minor GC est lancé. La place en S0 étant insuffisante pour accueillir tous les objets et/ou le tenured age étant atteint, des objets sont promus dans l'espace Old.

Le processus continue jusqu'à ce que la limite du taux de remplissage de la Old soit atteint.
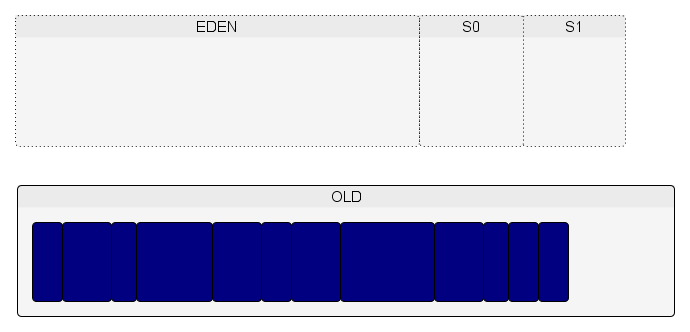
À ce moment-là, un Full GC est exécuté.
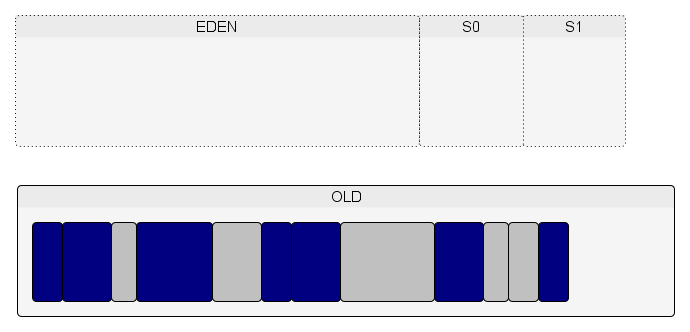
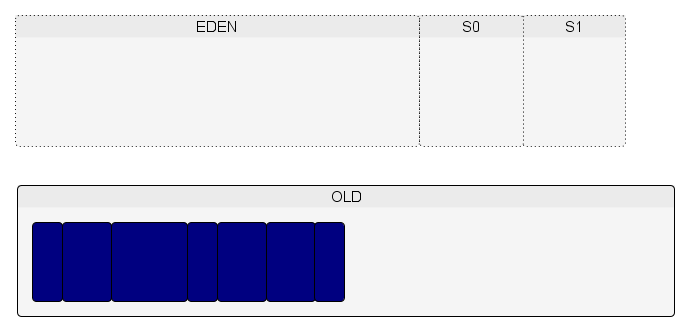
Donc on peut en conclure que le monitoring/profilling va perturber le fonctionnement du GC, car les objets en mémoire seront plus gros et plus nombreux. Qui dit objets plus gros et nombreux, dit moins d'objets en mémoire et plus de GC (minor et Full). De même, l'instrumentation des objets ralentira la vitesse de création des objets. Donc le fonctionnement de l'application est modifié.
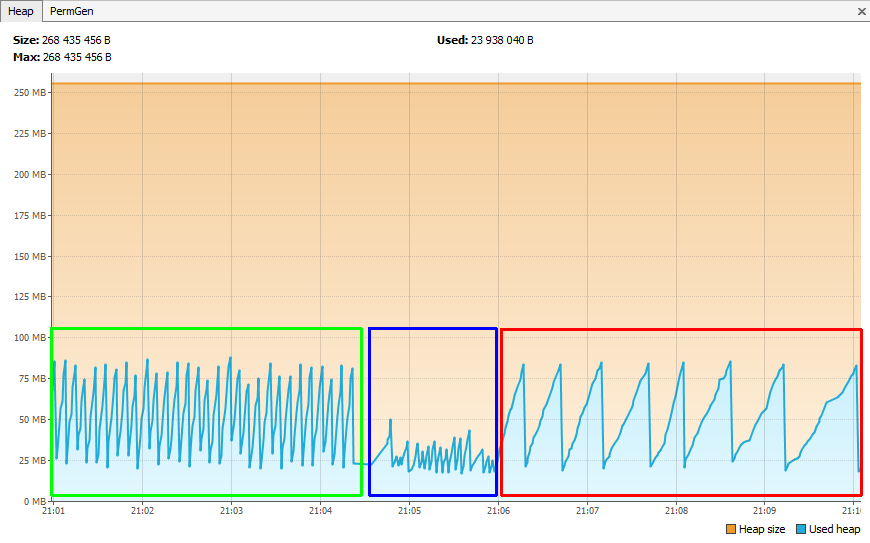
Voilà un test effectué sur Spring PetClinic qui montre bien la modification du comportement de l'application.
En vert, on peut voir les différentes courbes sans le monitoring.
En bleu, pendant la mise en place du monitoring.
En rouge, après la mise en place du monitoring.
On voit très bien le comportement du GC qui diffère avant et après avec une vitesse de création d'objets plus lente et donc des GC plus espacés.
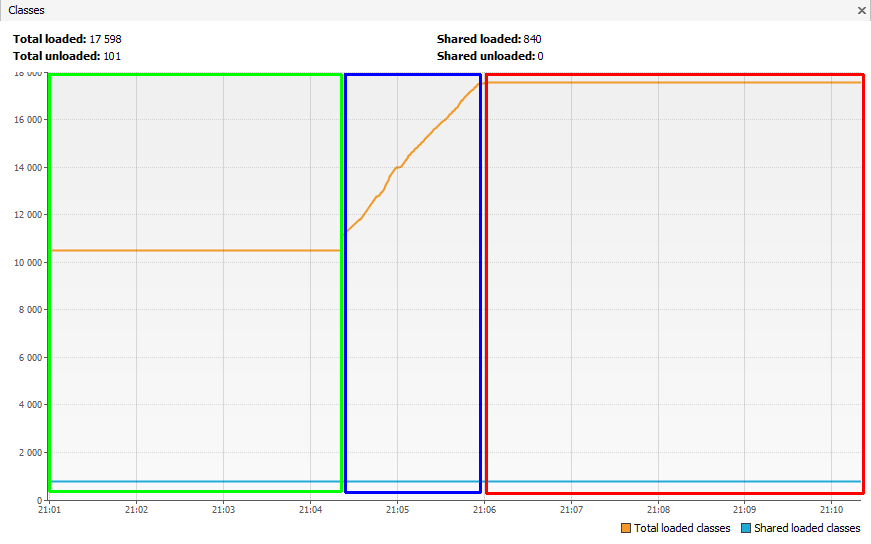
Le nombre de classes augmente.
Le nombre de threads augmente aussi.

Les temps de réponse se dégradent.
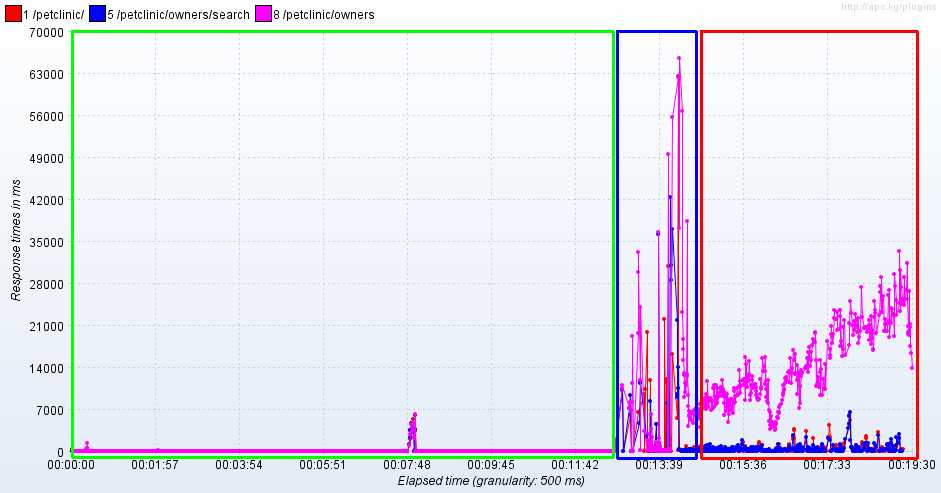
III-D. Interruption pour prendre des mesures▲
Lors de l'échantillonnage, tous les threads de l'application sont bloqués afin de récupérer leur stacktrace. Donc le comportement de la JVM est modifié et donc encore une fois les performances de l'application seront impactées.
III-E. Augmentation du nombre de classes▲
Afin d'instrumenter et de relever les mesures, de nouvelles classes vont être créées. Classes qui sans monitoring ne seraient pas créées et donc encore une fois l'application testée est modifiée.
Dans ce test, on voit que sans monitoring il y a 2606 classes créées et chargées.
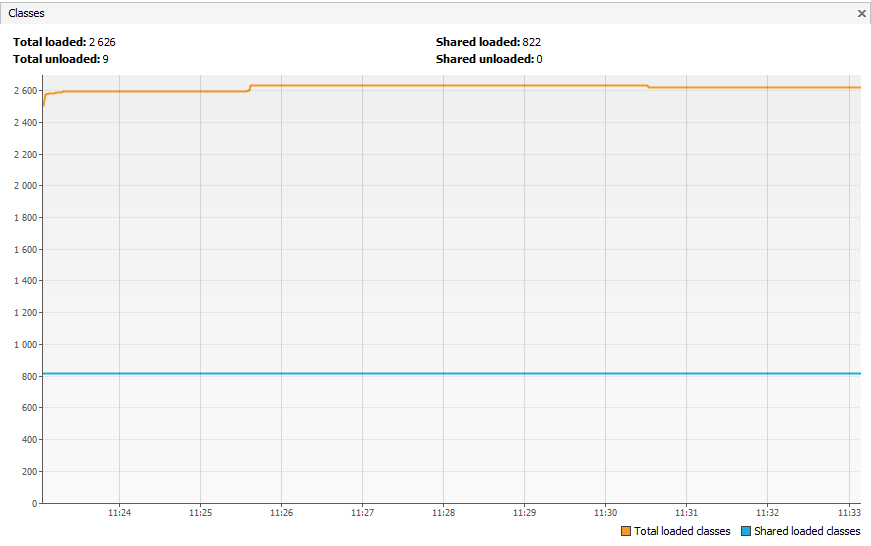
Une fois l'instrumentation activée on se retrouve avec 4401 classes.

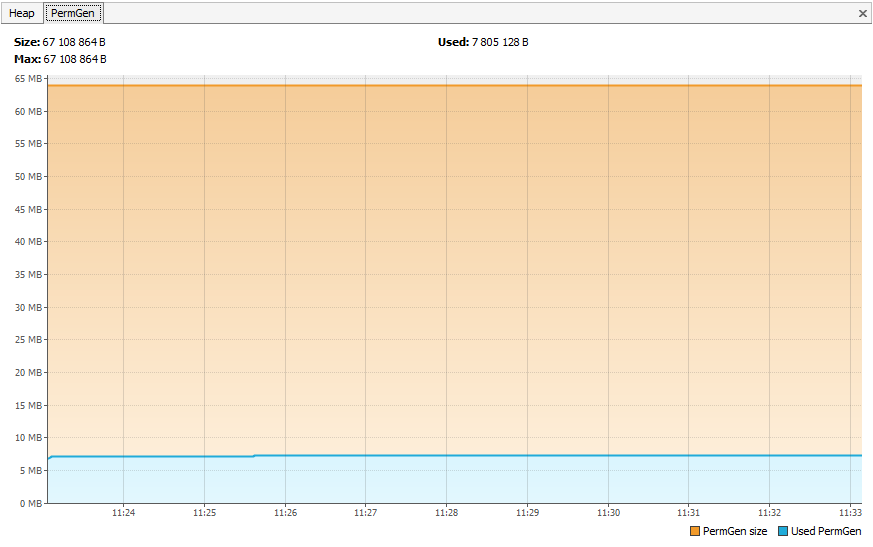
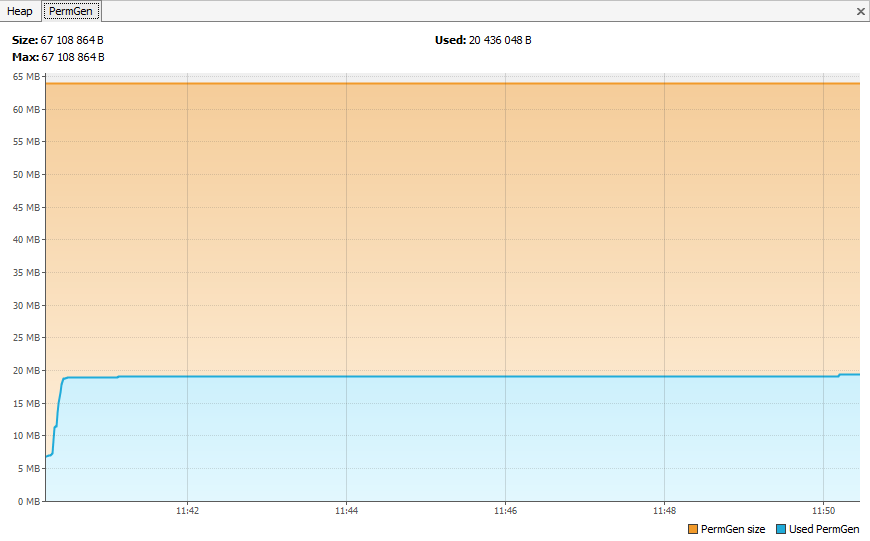
Ces classes se retrouveront dans la PermGen.
Sans monitoring.
Avec monitoring.
Et aussi dans la heap qui se remplira plus vite et donc augmentera le nombre de Garbage Collector nécessaires.
Sans monitoring.
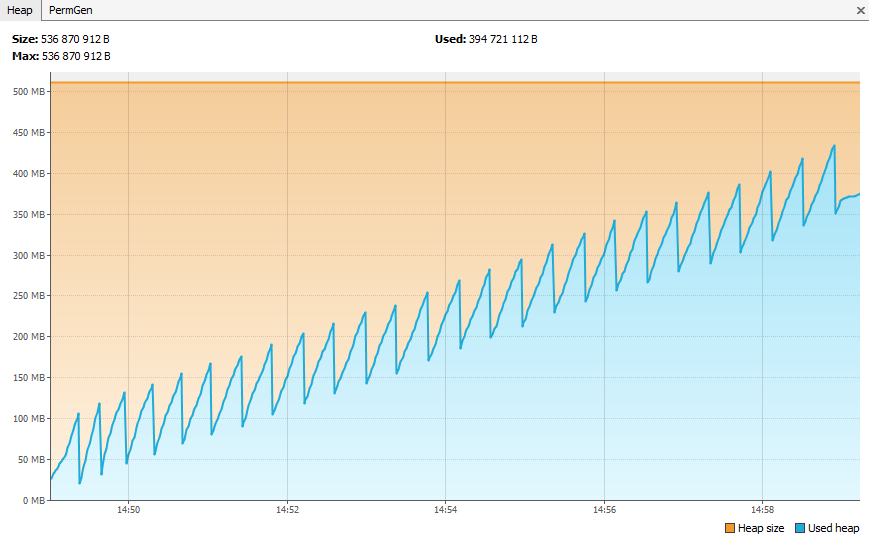
Avec monitoring.
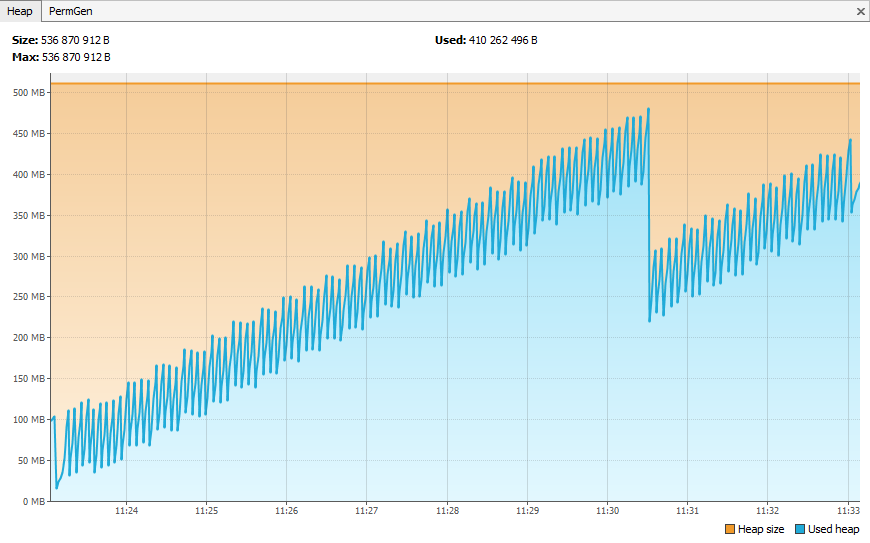
IV. Réduire l'overhead▲
Heureusement, il existe un certain nombre de solutions pour réduire le problème d'overhead.
IV-A. Bien choisir sa méthode de mesure▲
La première chose à faire est de bien choisir sa méthode de mesure (échantillonnage ou instrumentation) car l'overhead n'est pas le même en fonction de notre choix.
Par exemple avec VisualVM, on peut choisir l'un ou l'autre.

Ici Sampler équivaut à échantillonnage et Profiler équivaut à instrumentation.
Pour voir la différence, on va superviser JMeter lors d'un test de charge.
Sans monitoring on a ce comportement.

Maintenant, activons l'échantillonnage.
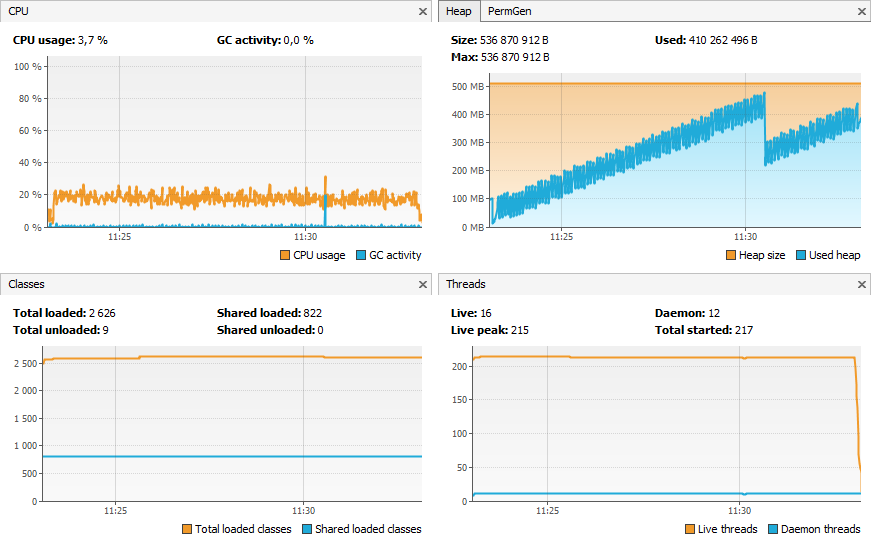
On remarque que la charge CPU fait plus que doubler.

Le comportement du Garbage Collector dans la heap est différent.
Faisons la même chose, mais en activant l'instrumentation.
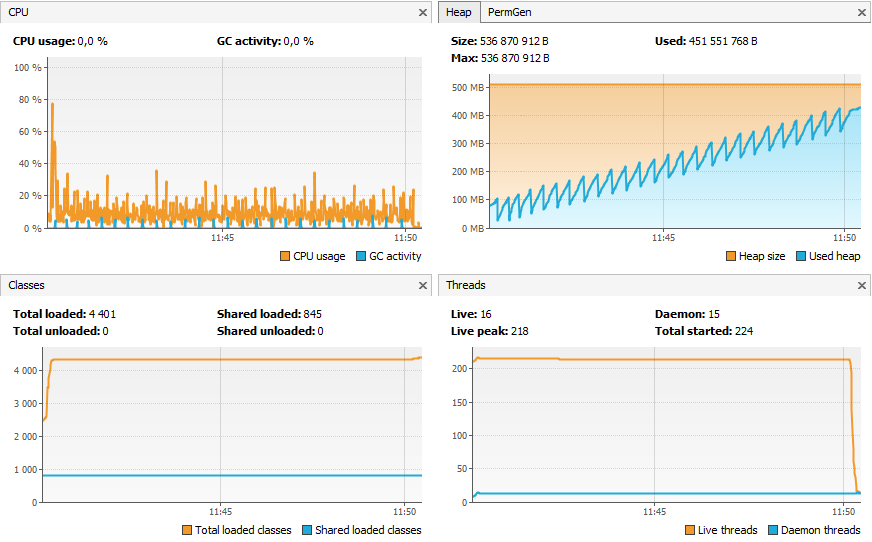
Cette fois-ci c'est le taux d'utilisation du processeur et le nombre de classes qui sont modifiés.
Faisons un autre test où nous ne regarderons que les temps de réponse.
Sans supervision on a.
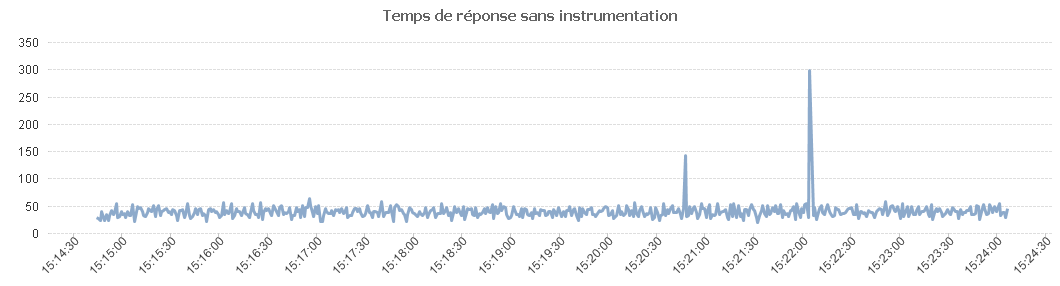
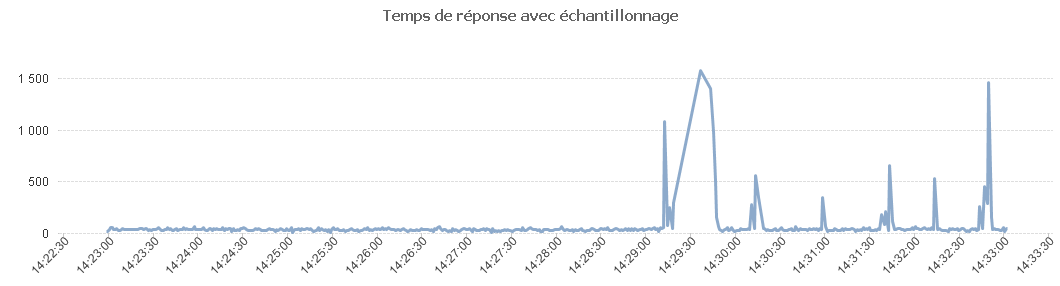
Avec l'échantillonnage on a.
Avec l'instrumentation on a.
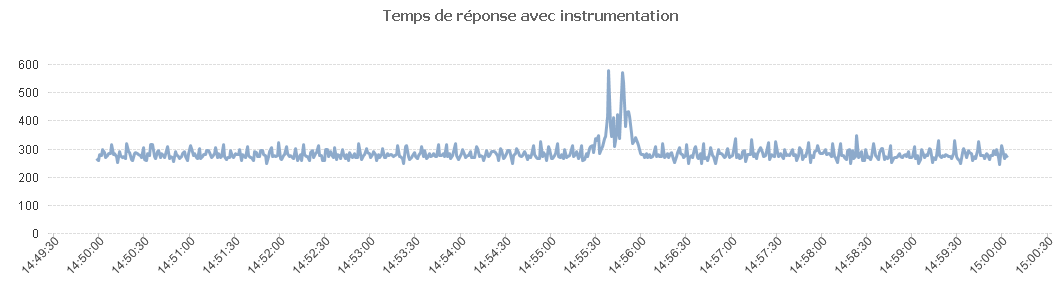
Comme on peut le voir dans le tableau ci-dessous, les temps de réponse ne sont pas les mêmes en fonction de la méthode de mesure choisie.
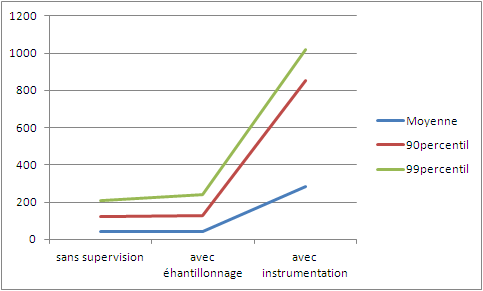
Chaque méthode de mesure a ses points forts et ses points faibles et en fonction du test que l'on veut réaliser, ce choix peut avoir un impact plus ou moins grand et donc il faut en tenir compte.
IV-B. Changer la fréquence des prises de mesures▲
En diminuant la fréquence des mesures, on réduit aussi l'overhead.
Il faut donc trouver un juste milieu entre la précision des résultats et l'overhead généré.
Attention à ne pas mettre une fréquence de mesures trop élevée sous peine d'avoir des mesures inutiles ou pire des résultats faux (overhead trop important, fréquence de mesures non atteinte…).
Voilà par exemple sous VisualVM où il faut modifier cette fréquence.
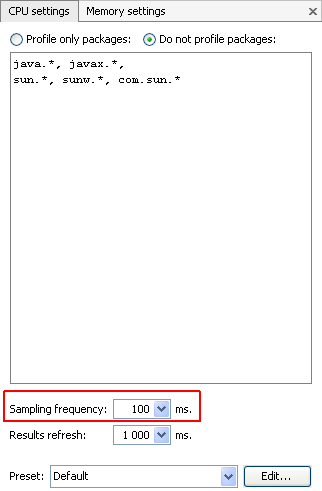
Faisons un test afin de voir l'overhead qu'une fréquence trop élevée peut engendrer.
Commençons par avoir des résultats de référence sans supervision.
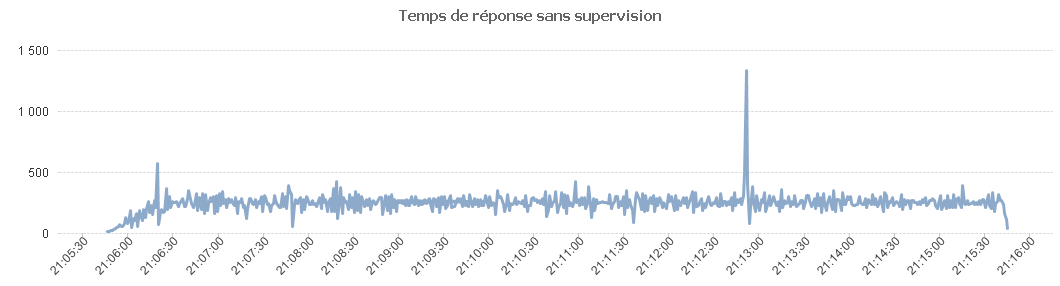
Maintenant, activons la supervision avec une fréquence d'échantillonnage de 10 000 ms.
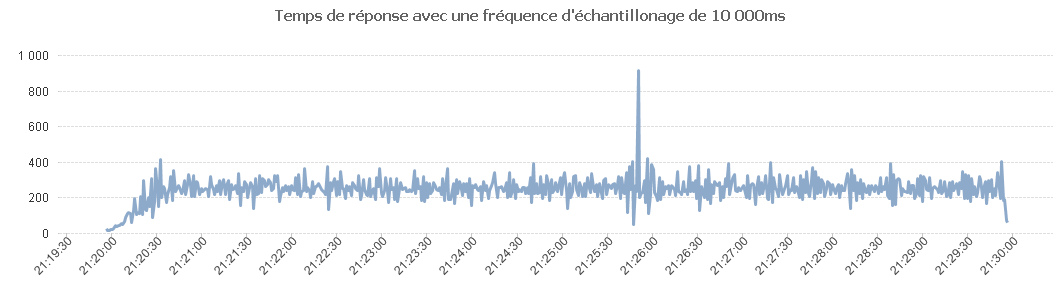
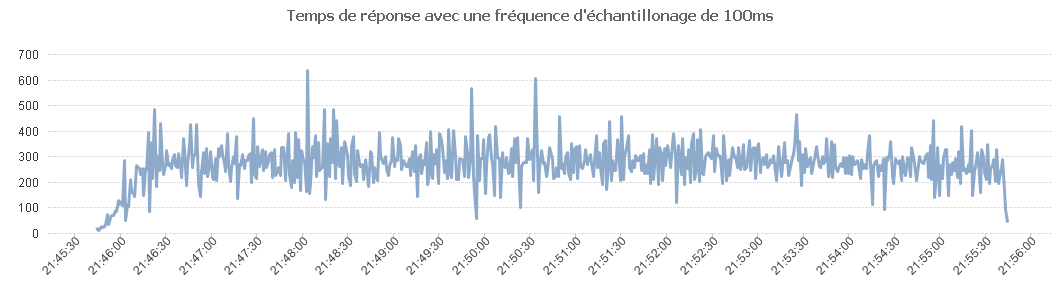
Puis avec une fréquence d'échantillonnage de 100 ms.
Et enfin avec une fréquence d'échantillonnage 20 ms.
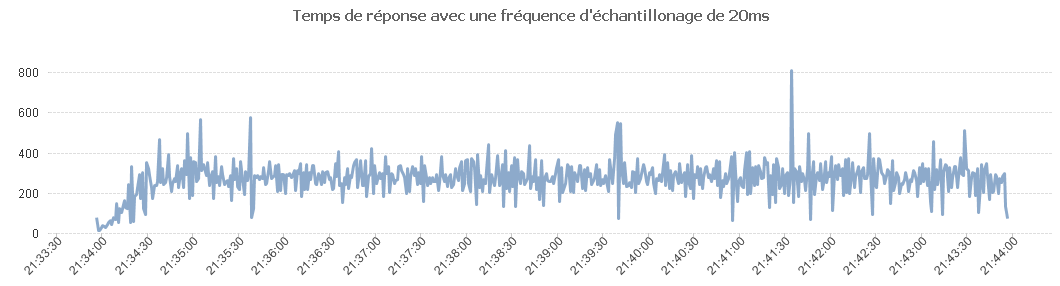
Comme on peut le voir sur ce tableau, les temps de réponse se dégradent.
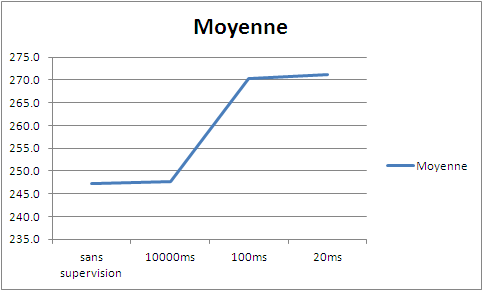
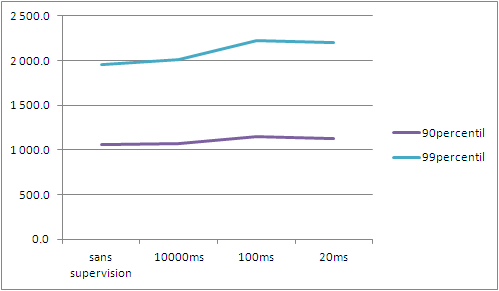
Je vous laisse imaginer et tester la dégradation des temps de réponse avec une application plus complexe et un test de charge plus poussé.
IV-C. Ne pas tout superviser▲
Tous les outils du marché permettent de mettre en place des filtres afin de limiter le nombre de classes à superviser.
Si ce n'est pas le cas, vous devez bien vous renseigner sur la méthodologie de collecte des métriques avant de vous lancer tête baissée dans un outil plutôt qu'un autre. (Collecte par instrumentation ou par échantillonnage…)
Attention, certains outils excluent certains frameworks/classes de leurs mesures avec la configuration de base.
Par exemple sous VisualVM.
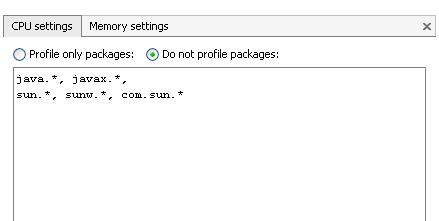
Premier test avec VisualVM, on laisse par défaut les paramètres d'instrumentation.
Maintenant, instrumentons toutes les classes.
Le test échoue à cause de l'overhead, on comprend pourquoi les outils excluent les frameworks/classes connues de leurs mesures.
Diminuons la couverture d'instrumentation.
Comme on peut le voir sur le tableau ci-dessous, l'impact sur les temps de réponse est énorme.
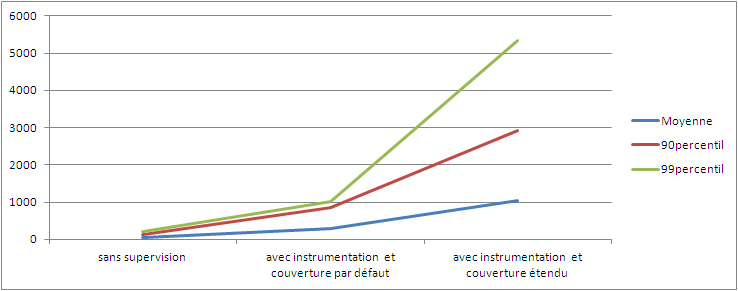
Je conseille de diminuer la couverture d'instrumentation au plus vite (par exemple une fois la partie du code posant problème détectée) lors des tests.
IV-D. Changer de version▲
Régulièrement, des mises à jour des outils sont proposées afin de réduire l'overhead.
Ne pas hésiter à lire le what's new de l'outil utilisé afin de chercher s'il a eu des améliorations de performance depuis la version utilisée.
IV-E. Changer d'outil▲
Si cela n'est pas suffisant, le changement de l'outil de monitoring/profiling peut être envisagé.
Le gain peut être spectaculaire, car certains outils ont pour but d'être utilisés en production alors que d'autres seulement en environnement de développement.
Attention à bien avoir le même périmètre (fréquence, classes instrumentées…) avant de comparer deux logiciels.
Prenons le test précédent de JMeter.
Pour rappel, voilà les indicateurs sans monitoring.
Prenons un outil non destiné aux tests en environnement de production.
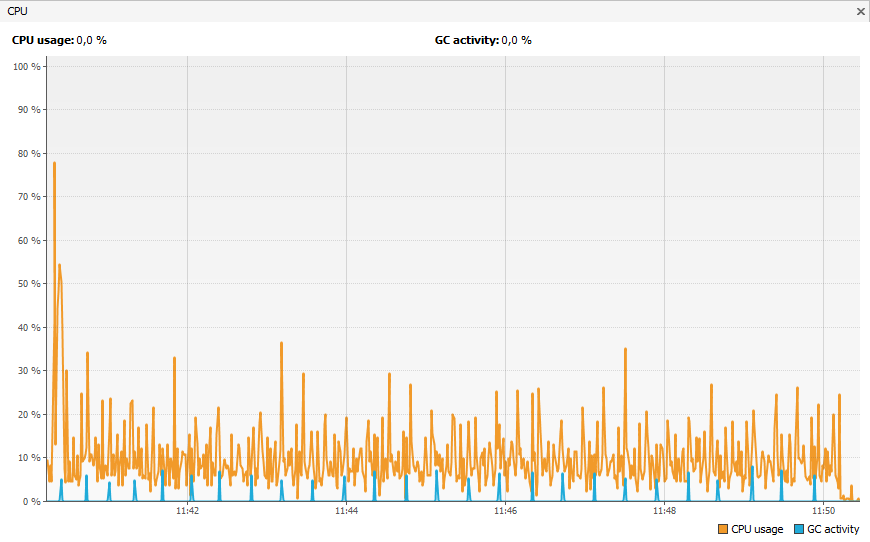
Maintenant, regardons les résultats du même test, mais avec un outil adapté aux tests en environnement de production.
Comme on peut le voir, il y a beaucoup moins d'overhead généré par le deuxième outil.
En particulier la consommation CPU. On remarque que l'overhead de l'outil dédié à la production a un overhead très bas et bien moins important que l'autre outil.
Sans monitoring.
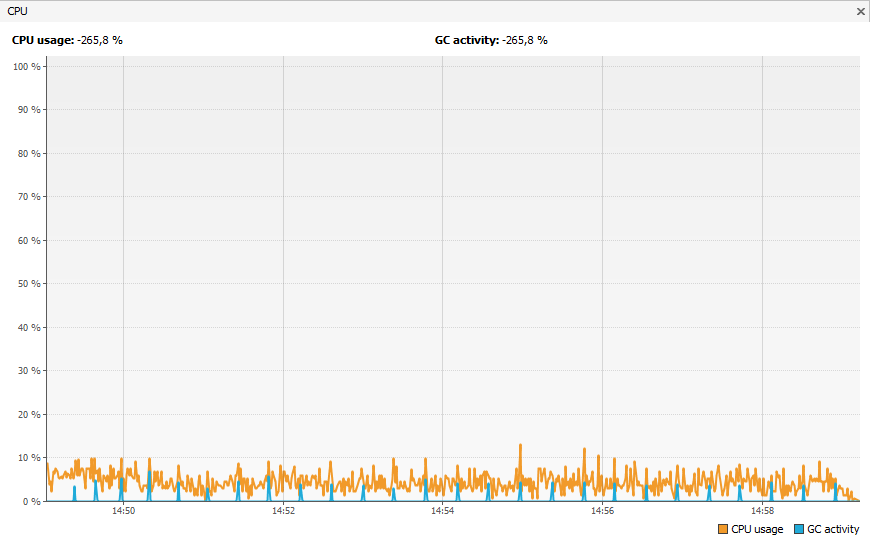
Outil adapté aux tests en environnement de production.
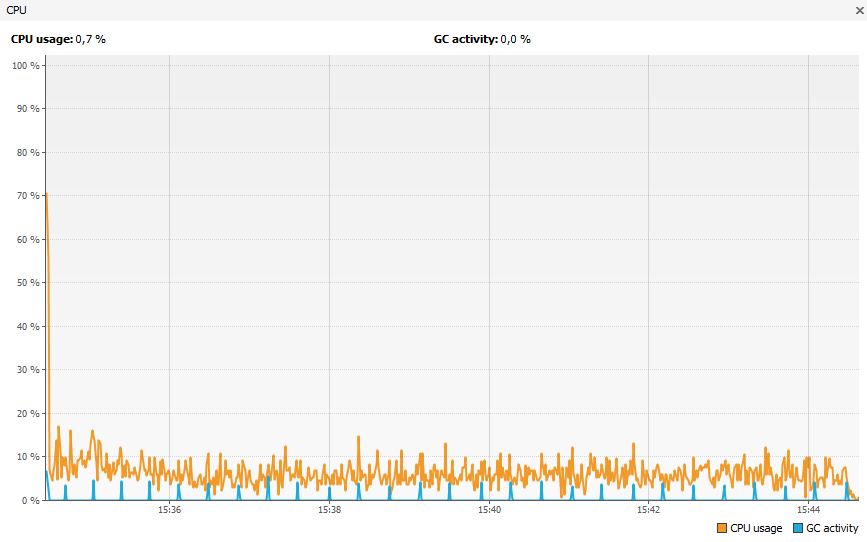
Outil non destiné aux tests en environnement de production.
Les résultats peuvent être beaucoup plus impressionnants si l'on pousse plus loin le test (plus de charges…) et/ou en prenant une application de test plus exigeante (faible latence…). Il ne faut pas hésiter à faire un POC (Proof Of Concept) avec différents outils sur votre application afin de déterminer l'outil le plus adapté à la situation.
V. Conclusion et remerciements▲
Comme nous l'avons vu, la mesure d'un système modifie son comportement.
L'impact de cette mesure (appelé overhead) peut être réduit de plusieurs manières. Pour cela, il faut bien comprendre ce que l'on mesure et l'outil utilisé en fonction de l'objectif du test réalisé.
Dans tous les cas, il ne faut pas oublier de prendre en compte cet overhead en fonction d'un certain nombre de paramètres (type d'application testé, des objectifs du test…).
Nous tenons à remercier Claude Leloup pour sa relecture attentive de cet article.