




I. Introduction▲
Maintenant que nous avons une méthode d'audit de performance et la possibilité de générer une base de données avec un gros volume, il est temps de regarder d'un peu plus près certaines parties d'un programme Java EE. Dans cette série d'articles, on commencera par la partie Hibernate en nous focalisant sur les performances et en particulier sur les stratégies de chargement pour ce premier article.
II. Présentation de Hibernate▲
Comme il est dit dans la FAQ, Hibernate est un framework de mapping objet/relationnel qui permet de manipuler les données d'une base de données relationnelle sous forme d'objet.
Pour plus d'informations sur Hibernate, il y a https://java.developpez.com/cours/?page=persistance-cat#hibernate.
III. Problèmes de performances avec Hibernate▲
De nombreux problèmes de performances peuvent arriver si on ne fait pas attention lors de l'utilisation de Hibernate.
En particulier :
- problèmes dits de N+1 ;
- mauvaise gestion des clés primaires auto-incrémentées ;
- sous utilisation des caches ;
- …
IV. Préparation de l'environnement de test▲
Afin d'avoir un environnement de test, nous allons le créer nous même à l'aide de Benerator et de Netbeans.
IV-A. Création du jeu de données avec Benerator▲
Nous allons utiliser Benerator pour générer un jeu de données sur PostreSQL.
Voilà notre schéma de base de données.
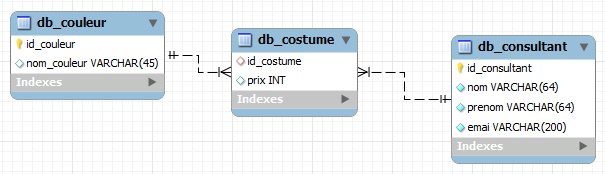
Afin d'avoir des traces les plus simples, nous nous contenterons d'un petit volume de données dans un premier temps.
Commençons par créer les tables nécessaires :
DROP SEQUENCE seq_hibernate_id_gen;
DROP TABLE t_costume;
DROP TABLE t_consultant;
DROP TABLE t_couleur;CREATE SEQUENCE seq_hibernate_id_gen start 1;
CREATE TABLE t_couleur (
id_couleur int NOT NULL,
nom_couleur varchar(64) NOT NULL,
PRIMARY KEY (id_couleur)
);
CREATE TABLE t_consultant (
id_consultant int NOT NULL,
nom varchar(64),
prenom varchar(64),
email varchar(64),
PRIMARY KEY (id_consultant)
);
CREATE TABLE t_costume (
id_costume int NOT NULL,
couleur_fk int NOT NULL,
consultant_fk int NOT NULL,
prix int NOT NULL,
PRIMARY KEY (id_costume),
CONSTRAINT t_costume_couleur_fk FOREIGN KEY (couleur_fk) REFERENCES t_couleur (id_couleur),
CONSTRAINT t_costume_consultant_fk FOREIGN KEY (consultant_fk) REFERENCES t_consultant (id_consultant)
);
Puis nous utiliserons un fichier CSV pour importer les couleurs :
"id_couleur","nom_couleur",
1,"gris"
2,"bleu"
3,"noir"
4,"marron"
5,"vert"
Maintenant il ne reste plus qu'à générer les données :
<?xml version="1.0" encoding="iso-8859-1"?>
<setup xmlns="http://databene.org/benerator/0.6.3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://databene.org/benerator/0.6.3 http://databene.org/benerator-0.6.3.xsd">
<import platforms="db" />
<database id="db" url="jdbc:postgresql://localhost:5432/postgres" driver="org.postgresql.Driver"
schema="public" user="benerator" password="benerator" batch="true" fetchSize="1000"/>
<execute uri="drop_tables.sql" target="db" onError="ignore"/>
<execute uri="create_tables.sql" target="db" optimize="true"/>
<bean id="idGen" spec="new DBSeqHiLoGenerator('seq_hibernate_id_gen', 1, db)" />
<iterate source="t_couleur.import.csv" type="t_couleur" encoding="utf-8" consumer="db" />
<generate type="t_consultant" count="5" consumer="db" pageSize="1000" >
<variable name="individu" generator="org.databene.domain.person.PersonGenerator" dataset="FR" locale="fr"/>
<id name="id_consultant" generator="idGen" />
<attribute name="prenom" script="individu.givenName" />
<attribute name="nom" script="individu.familyName" />
<attribute name="email" script="individu.email" />
</generate>
<generate type="t_costume" count="15" consumer="db" pageSize="1000">
<id name="id_costume" generator="idGen" />
<attribute name="prix" min="100" max="2000" />
<reference name="couleur_fk" targetType="t_couleur" source="db" distribution="random" />
<reference name="consultant_fk" targetType="t_consultant" source="db" distribution="random" cyclic="true" />
</generate>
</setup>IV-B. Mapping et configuration de Hibernate▲
De nombreuses solutions existent afin de nous aider dans cette tâche.
Par exemple nous pouvons utiliser Netbeans 6.9 afin de générer les fichiers de mapping et de configuration de Hibernate.
On utilise l'assistant pour la création du fichier de configuration de Hibernate.
Commençons par créer le fichier de configuration et ajouter les librairies Hibernate au projet.

Puis configurons le comportement de l'outil de génération du mapping avec le fichier reveng.xml.
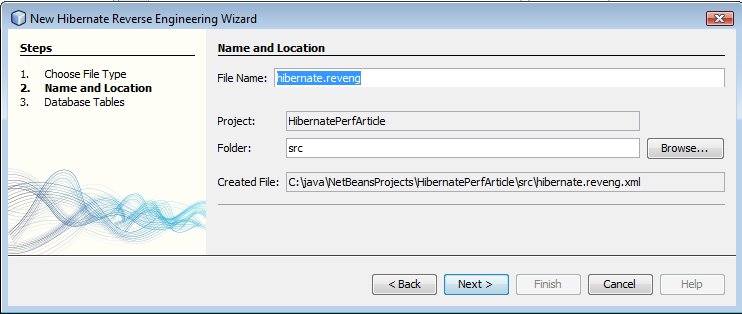

Puis générons les fichiers de mapping.
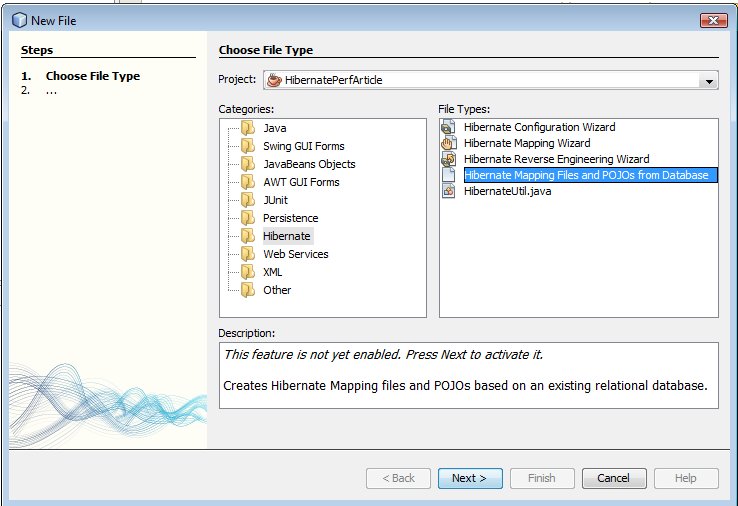
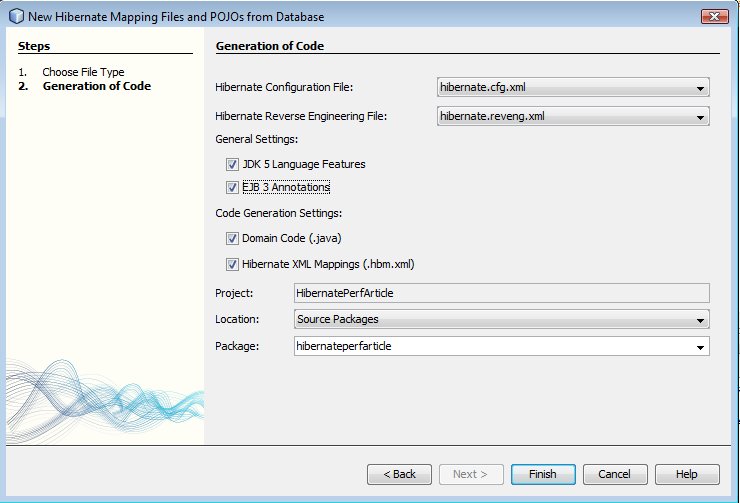
On ajoute la classe HibernateUtil pour simplifier la gestion de Hibernate.
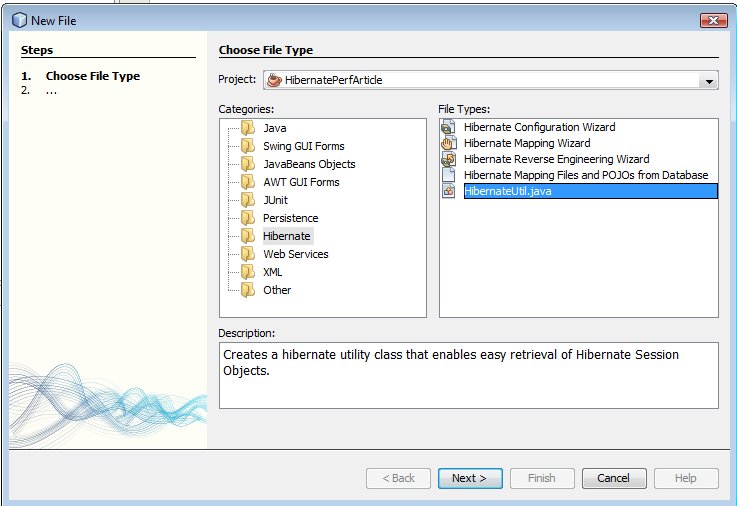
Ne pas oublier d'ajouter la librairie log4j pour avoir les logs.
V. Préconisations▲
Mes préconisations sont :
- toujours développer avec Hibernate avec les traces activées et ne pas croire que Hibernate va optimiser les requêtes par magie ;
- initialiser les relations en mode différé/lazzy ;
- puis au cas par cas s'assurer que ce mode de chargement ne génère pas les problèmes dits de N+1 ou les produits cartésiens ;
- optimiser les modes de chargement en utilisant les techniques de chargement par jointure, chargement par sous-select ;
- bien travailler les index, jointures ;
- faire appel à un DBA.
VI. Récupérer les informations de fonctionnement de Hibernate▲
Avant de commencer l'optimisation de la configuration de Hibernate et de son mapping, il faut bien s'assurer :
- d'avoir un jeu de données en base assez important, car sinon on passera à côté de certains problèmes qui n'apparaissent qu’à forte volumétrie ;
- d'avoir un serveur de bases de données un minimum bien configuré (en particulier sa mémoire cache) et donc faire appel à un DBA ;
- des scénarios réalistes ;
- monitorer tous les serveurs afin que la charge de travaille soit bien répartie.
Une des premières choses à faire est d'activer les logs de Hibernate ou d'utiliser les bons outils afin de savoir ce qu'il se passe. Cela nous permettra de récupérer les requêtes SQL générées pour affiner le tuning de la base de données (ajout d'index, optimisation des tables space…) et de valider le paramétrage de Hibernate.
Regardons comment activer les traces de Hibernate.
VI-A. Tracer les requêtes SQL▲
La première chose à faire est d'activer la journalisation des requêtes générées.
Cela se fait dans le fichier log4j.properties :
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
log4j.rootLogger=info, stdout
# Trace toutes les requêtes SQL de type DML (gestion des données)
log4j.logger.org.hibernate.SQL=debug
# Trace toutes les requêtes SQL de type DDL (gestion de la structure de la base)
log4j.logger.org.hibernate.tool.hbm2ddl=debugOu activer les propriétés hibernate.show_sql et sql_comments dans le fichier hibernate.cfg.xml
Le code suivant :
TCostume costume = (TCostume) session.load(TCostume.class, 4113);
System.out.println(costume.getIdCostume());
System.out.println(costume.getTConsultant().getNom());Produira les traces suivantes :
select tcostume0_.id_costume as id1_1_0_, tcostume0_.consultant_fk as consultant2_1_0_,
tcostume0_.couleur_fk as couleur3_1_0_, tcostume0_.prix as prix1_0_ from public.t_costume tcostume0_ where tcostume0_.id_costume=?
select tconsultan0_.id_consultant as id1_2_0_, tconsultan0_.nom as nom2_0_, tconsultan0_.prenom as prenom2_0_,
tconsultan0_.email as email2_0_ from public.t_consultant tconsultan0_ where tconsultan0_.id_consultant=?Afin de formater les requêtes SQL, on pourra activer la propriété hibernate.format_sql dans le fichier hibernate.cfg.xml. Pour cela ajouter :
<property name="hibernate.format_sql">true</property>Ou utiliser l'assistant de Netbeans.
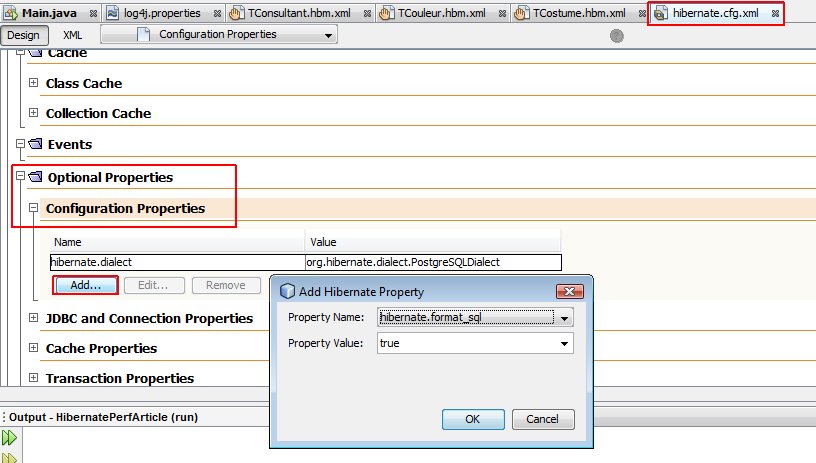
Et dorénavant, on aura des traces formatées de la manière suivante :
select
tcostume0_.id_costume as id1_1_0_,
tcostume0_.consultant_fk as consultant2_1_0_,
tcostume0_.couleur_fk as couleur3_1_0_,
tcostume0_.prix as prix1_0_
from
public.t_costume tcostume0_
where
tcostume0_.id_costume=?
select
tconsultan0_.id_consultant as id1_2_0_,
tconsultan0_.nom as nom2_0_,
tconsultan0_.prenom as prenom2_0_,
tconsultan0_.email as email2_0_
from
public.t_consultant tconsultan0_
where
tconsultan0_.id_consultant=?Et si on veut savoir l'origine de la requête, il suffit d'ajouter dans le fichier hibernate.cfg.xml :
<property name="use_sql_comments">true</property>Pour obtenir :
/* load hibernatep.TCostume */ select
tcostume0_.id_costume as id1_1_0_,
tcostume0_.consultant_fk as consultant2_1_0_,
tcostume0_.couleur_fk as couleur3_1_0_,
tcostume0_.prix as prix1_0_
from
public.t_costume tcostume0_
where
tcostume0_.id_costume=?
/* load hibernatep.TConsultant */ select
tconsultan0_.id_consultant as id1_2_0_,
tconsultan0_.nom as nom2_0_,
tconsultan0_.prenom as prenom2_0_,
tconsultan0_.email as email2_0_
from
public.t_consultant tconsultan0_
where
tconsultan0_.id_consultant=?Ne pas oublier de les désactiver pour les autres tests de performance et pour la mise en production de l'application.
VI-B. Tracer la valeur des paramètres hibernate▲
Dans le fichier log4j.properties :
log4j.logger.org.hibernate.type=debugCe qui nous donnera :
14:11:45,541 DEBUG SQL:401 - select tcustomer0_.id as id0_, tcustomer0_.address_fk as address2_0_, tcustomer0_.login as login0_,
tcustomer0_.password as password0_, tcustomer0_.firstname as firstname0_, tcustomer0_.lastname as lastname0_, tcustomer0_.telephone as telephone0_, tcustomer0_.email as email0_,
tcustomer0_.date_of_birth as date9_0_ from public.t_customer tcustomer0_ where tcustomer0_.id=1002VI-C. Tracer les transactions Hibernate▲
Dans le fichier log4j.properties :
log4j.logger.org.hibernate.transaction=debugCe qui nous donnera :
DEBUG JDBCTransaction:54 - begin
DEBUG JDBCTransaction:59 - current autocommit status: false
DEBUG SQL:401 - select tcustomer0_.id as id0_, tcustomer0_.address_fk as address2_0_, tcustomer0_.login as login0_, tcustomer0_.password as password0_,
tcustomer0_.firstname as firstname0_, tcustomer0_.lastname as lastname0_, tcustomer0_.telephone as telephone0_, tcustomer0_.email as email0_,
tcustomer0_.date_of_birth as date9_0_ from public.t_customer tcustomer0_ where tcustomer0_.id=1002
1: Paul
DEBUG JDBCTransaction:103 - commit
DEBUG JDBCTransaction:116 - committed JDBC ConnectionVI-D. Tracer toute acquisition de ressource JDBC▲
Dans le fichier log4j.properties :
log4j.logger.org.hibernate.jdbc=debugCe qui nous donnera :
DEBUG ConnectionManager:421 - opening JDBC connection
DEBUG AbstractBatcher:366 - about to open PreparedStatement (open PreparedStatements: 0, globally: 0)
DEBUG SQL:401 - select tcustomer0_.id as id0_, tcustomer0_.address_fk as address2_0_, tcustomer0_.login as login0_, tcustomer0_.password as password0_,
tcustomer0_.firstname as firstname0_, tcustomer0_.lastname as lastname0_, tcustomer0_.telephone as telephone0_, tcustomer0_.email as email0_,
tcustomer0_.date_of_birth as date9_0_ from public.t_customer tcustomer0_ where tcustomer0_.id=1002
DEBUG AbstractBatcher:382 - about to open ResultSet (open ResultSets: 0, globally: 0)
DEBUG AbstractBatcher:389 - about to close ResultSet (open ResultSets: 1, globally: 1)
DEBUG AbstractBatcher:374 - about to close PreparedStatement (open PreparedStatements: 1, globally: 1)
1: Paul
DEBUG ConnectionManager:404 - aggressively releasing JDBC connection
DEBUG ConnectionManager:441 - releasing JDBC connection [ (open PreparedStatements: 0, globally: 0) (open ResultSets: 0, globally: 0)]
BUILD SUCCESSFUL (total time: 1 second)VI-E. Statistiques Hibernate▲
Si on active hibernate.generate_statistics, Hibernate va fournir un certain nombre de métriques via SessionFactory.getStatistics().
Pour cela, dans le fichier hibernate.cfg.xml. Ajoutons :
<property name="hibernate.generate_statistics">true</property>Puis dans le code source :
Statistics stats = HibernateUtil.getSessionFactory().getStatistics();
...
stats.logSummary();donnera :
INFO StatisticsImpl:463 - Logging statistics....
INFO StatisticsImpl:464 - start time: 1280654979840
INFO StatisticsImpl:465 - sessions opened: 1
INFO StatisticsImpl:466 - sessions closed: 1
INFO StatisticsImpl:467 - transactions: 1
INFO StatisticsImpl:468 - successful transactions: 1
INFO StatisticsImpl:469 - optimistic lock failures: 0
INFO StatisticsImpl:470 - flushes: 1
INFO StatisticsImpl:471 - connections obtained: 1
INFO StatisticsImpl:472 - statements prepared: 2
INFO StatisticsImpl:473 - statements closed: 2
INFO StatisticsImpl:474 - second level cache puts: 0
INFO StatisticsImpl:475 - second level cache hits: 0
INFO StatisticsImpl:476 - second level cache misses: 0
INFO StatisticsImpl:477 - entities loaded: 2
INFO StatisticsImpl:478 - entities updated: 0
INFO StatisticsImpl:479 - entities inserted: 0
INFO StatisticsImpl:480 - entities deleted: 0
INFO StatisticsImpl:481 - entities fetched (minimize this): 2
INFO StatisticsImpl:482 - collections loaded: 0
INFO StatisticsImpl:483 - collections updated: 0
INFO StatisticsImpl:484 - collections removed: 0
INFO StatisticsImpl:485 - collections recreated: 0
INFO StatisticsImpl:486 - collections fetched (minimize this): 0
INFO StatisticsImpl:487 - queries executed to database: 0
INFO StatisticsImpl:488 - query cache puts: 0
INFO StatisticsImpl:489 - query cache hits: 0
INFO StatisticsImpl:490 - query cache misses: 0
INFO StatisticsImpl:491 - max query time: 0msSi on ne veut pas autant d'informations, on peut spécifier celles que l'on veut.
Par exemple : stats.getQueryCacheMissCount(), stats.getEntityDeleteCount(), stats.getCollectionLoadCount(), stats.getFlushCount()…
VI-F. JMX▲
Il est bien sûr possible de récupérer un certain nombre d'informations à l'aide de JMX.
Plus d'information sur http://docs.jboss.org/hibernate/core/3.5/reference/fr-FR/html/performance.html#performance-monitoring
VII. Configuration du mapping▲
Maintenant que nous avons un moyen de mesurer et de comprendre ce qu'il se passe, penchons-nous sur l'affinement du mapping des tables.
Hibernate permet la manipulation des enregistrements sous forme de graphe d'objets, graphe d'objets qu'il faut charger en mémoire avec les risques que cela implique (temps d'exécution couteux, grosse consommation mémoire…). Heureusement, Hibernate propose un certain nombre de stratégies de chargement.
VII-A. Stratégies de chargement▲
La stratégie de chargement dépendant du contexte (type de requête, paramètres de la requête…) il est plus judicieux de définir des paramètres par défauts dans les fichiers de mapping et de surcharger pour une transaction particulière à l'aide de left join fetch dans les requêtes HQL ou d'utiliser la méthode setFetchMode(FetchMode.JOIN) dans l'API Criteria.
Les stratégies de chargement peuvent être paramétrées à l'aide de paramètres divisés en deux groupes. Le « comment » et le « quand ».
Voyons d'un peu plus près les différentes stratégies de chargement.
VII-A-1. Comment (quelle requête SQL est utilisée)▲
VII-A-1-a. Chargement par select▲
Hibernate récupère les données associées dans un second SELECT.
C'est le comportement par défaut de Hibernate.
Attention le chargement par select est très vulnérable au problème du N+1 selects.
VII-A-1-a-i. Exemple 1 : Récupération du propriétaire d'un costume▲
Regardons comment récupérer le propriétaire d'un costume :
Session session = HibernateUtil.getSessionFactory().openSession();
session.beginTransaction();
TCostume costume = (TCostume) session.load(TCostume.class, 4113);
System.out.println(costume.getIdCostume());
TConsultant proprio = costume.getTConsultant();
System.out.println(proprio.getNom());
session.getTransaction().commit();
session.close();Génèrera deux requêtes SQL.

select
tcostume0_.id_costume as id1_1_0_,
tcostume0_.consultant_fk as consultant2_1_0_,
tcostume0_.couleur_fk as couleur3_1_0_,
tcostume0_.prix as prix1_0_
from
public.t_costume tcostume0_
where
tcostume0_.id_costume=?
select
tconsultan0_.id_consultant as id1_0_0_,
tconsultan0_.nom as nom0_0_,
tconsultan0_.prenom as prenom0_0_,
tconsultan0_.email as email0_0_
from
public.t_consultant tconsultan0_
where
tconsultan0_.id_consultant=?La première récupère les informations du costume recherché et la 2e les informations sur le propriétaire.
C'est dommage d'utiliser deux requêtes SQL pour ce résultat alors qu'une seul aurait pu suffire. C'est dans ce cas la que la stratégie de chargement par jointure joue un rôle.
VII-A-1-a-ii. Exemple 2 : Récupération de la liste des costumes d'un consultant▲
Maintenant on va faire le contraire, on veut la liste des costumes par consultant :
TConsultant consultant = (TConsultant) session.get(TConsultant.class, 4108);
Set sets = consultant.getTCostumes();
for (Iterator iter = sets.iterator(); iter.hasNext();) {
TCostume costume = (TCostume) iter.next();
System.out.println(costume.getIdCostume());
}Génèrera deux requêtes SQL (une pour récupérer l'identifiant du costume associé au consultant avec l'identifiant 4108, puis une pour récupérer les informations de la table costume). C'est le problème dit de N+1
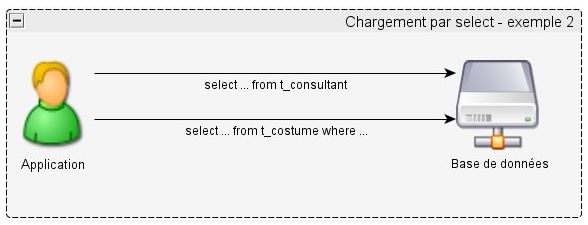
select
tconsultan0_.id_consultant as id1_0_,
tconsultan0_.nom as nom0_,
tconsultan0_.prenom as prenom0_,
tconsultan0_.email as email0_
from
public.t_consultant tconsultan0_
select
tcostumes0_.consultant_fk as consultant2_1_,
tcostumes0_.id_costume as id1_1_,
tcostumes0_.id_costume as id1_1_0_,
tcostumes0_.consultant_fk as consultant2_1_0_,
tcostumes0_.couleur_fk as couleur3_1_0_,
tcostumes0_.prix as prix1_0_
from
public.t_costume tcostumes0_
where
tcostumes0_.consultant_fk=?VII-A-1-b. Chargement par jointure▲
Hibernate récupère les données associées dans un même SELECT à l'aide d'un OUTER JOIN.
Pour utiliser cette stratégie, on a trois choix :
- utiliser fetch=« join » dans l'association (dans le fichier de mapping) ;
- utiliser left join fetch dans les requêtes HQL ;
- utiliser la méthode setFetchMode(FetchMode.JOIN) dans les criteria.
Il faudra faire attention à se retrouver avec des requêtes trop complexes comportant trop de jointures.
VII-A-1-b-i. Exemple 3 : Récupération du propriétaire d'un costume▲
Pour sélectionner cette stratégie, on peut positionner à join le paramètre fetch dans le fichier de mapping de TCostume :
<many-to-one name="TConsultant" class="hibernateperfarticle.TConsultant" fetch="join">
<column name="consultant_fk" not-null="true" />
</many-to-one>Le même code que précédemment :
TCostume costume = (TCostume) session.load(TCostume.class, 4113);
System.out.println(costume.getIdCostume());
TConsultant proprio = costume.getTConsultant();
System.out.println(proprio.getNom());Donnera cette fois une seule requête :

select
tcostume0_.id_costume as id1_1_1_,
tcostume0_.consultant_fk as consultant2_1_1_,
tcostume0_.couleur_fk as couleur3_1_1_,
tcostume0_.prix as prix1_1_,
tconsultan1_.id_consultant as id1_0_0_,
tconsultan1_.nom as nom0_0_,
tconsultan1_.prenom as prenom0_0_,
tconsultan1_.email as email0_0_
from
public.t_costume tcostume0_
inner join
public.t_consultant tconsultan1_
on tcostume0_.consultant_fk=tconsultan1_.id_consultant
where
tcostume0_.id_costume=?Donc si on sait que l'on va utiliser les informations des tables jointes, l'utilisation de la stratégie par jointure est une bonne idée.
Mais comme cela dépend des cas, il est plus judicieux de surcharger pour une transaction particulière à l'aide de left join fetch dans les requêtes HQL.
Query query = session.createQuery("from TCostume where idCostume=4113");
Iterator it = query.list().iterator();
while (it.hasNext()) {
TCostume costume = (TCostume) it.next();
System.out.println(costume.getIdCostume() + " : " + costume.getTConsultant().getNom());
}produira :
select
tcostume0_.id_costume as id1_1_,
tcostume0_.consultant_fk as consultant2_1_,
tcostume0_.couleur_fk as couleur3_1_,
tcostume0_.prix as prix1_
from
public.t_costume tcostume0_
where
tcostume0_.id_costume=4113
select
tconsultan0_.id_consultant as id1_0_0_,
tconsultan0_.nom as nom0_0_,
tconsultan0_.prenom as prenom0_0_,
tconsultan0_.email as email0_0_
from
public.t_consultant tconsultan0_
where
tconsultan0_.id_consultant=?Alors que si on surcharge la stratégie de chargement :
Query query = session.createQuery("from TCostume cos left join fetch cos.TConsultant where cos.idCostume=4113");
Iterator it = query.list().iterator();
while (it.hasNext()) {
TCostume costume = (TCostume) it.next();
System.out.println(costume.getIdCostume() + " : " + costume.getTConsultant().getNom());
}on aura ;
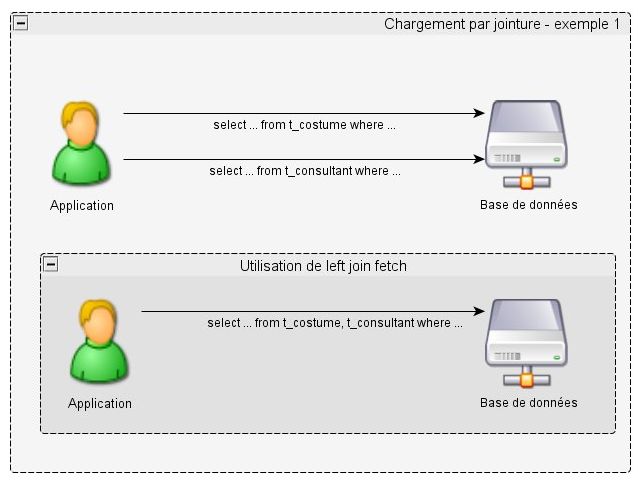
select
tcostume0_.id_costume as id1_1_0_,
tconsultan1_.id_consultant as id1_0_1_,
tcostume0_.consultant_fk as consultant2_1_0_,
tcostume0_.couleur_fk as couleur3_1_0_,
tcostume0_.prix as prix1_0_,
tconsultan1_.nom as nom0_1_,
tconsultan1_.prenom as prenom0_1_,
tconsultan1_.email as email0_1_
from
public.t_costume tcostume0_
left outer join
public.t_consultant tconsultan1_
on tcostume0_.consultant_fk=tconsultan1_.id_consultant
where
tcostume0_.id_costume=4113De même pour l'API Criteria il faudra utiliser la méthode setFetchMode(FetchMode.JOIN).
VII-A-1-b-ii. Exemple 4 : Récupération de la liste des costumes d'un consultant▲
On reprend le même code que précédemment pour récupérer la liste des costumes par consultant :
TConsultant consultant = (TConsultant) session.get(TConsultant.class, 4108);
Set sets = consultant.getTCostumes();
for (Iterator iter = sets.iterator(); iter.hasNext();) {
TCostume costume = (TCostume) iter.next();
System.out.println(costume.getIdCostume());
}On active le chargement par jointure dans le fichier Tconsultant.hbm.xml :
<set name="TCostumes" inverse="true" fetch="join">
<key>
<column name="consultant_fk" not-null="true" />
</key>
<one-to-many class="hibernateperfarticle.TCostume"/>
</set>Et cette fois-ci, on n'a plus qu'une seule requête SQL au lieu de deux :
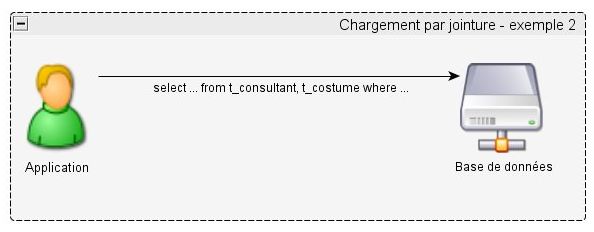
select
tconsultan0_.id_consultant as id1_0_1_,
tconsultan0_.nom as nom0_1_,
tconsultan0_.prenom as prenom0_1_,
tconsultan0_.email as email0_1_,
tcostumes1_.consultant_fk as consultant2_3_,
tcostumes1_.id_costume as id1_3_,
tcostumes1_.id_costume as id1_1_0_,
tcostumes1_.consultant_fk as consultant2_1_0_,
tcostumes1_.couleur_fk as couleur3_1_0_,
tcostumes1_.prix as prix1_0_
from
public.t_consultant tconsultan0_
left outer join
public.t_costume tcostumes1_
on tconsultan0_.id_consultant=tcostumes1_.consultant_fk
where
tconsultan0_.id_consultant=?Le même résultat sera obtenu avec l'API Criteria :
TConsultant consultant = (TConsultant) session.createCriteria(TConsultant.class)
.add(Restrictions.eq("idConsultant", Integer.valueOf(4108)))
.setFetchMode("TCostumes", FetchMode.JOIN).uniqueResult();
Set sets = consultant.getTCostumes();
for (Iterator iter = sets.iterator(); iter.hasNext();) {
TCostume costume = (TCostume) iter.next();
System.out.println(costume.getIdCostume());
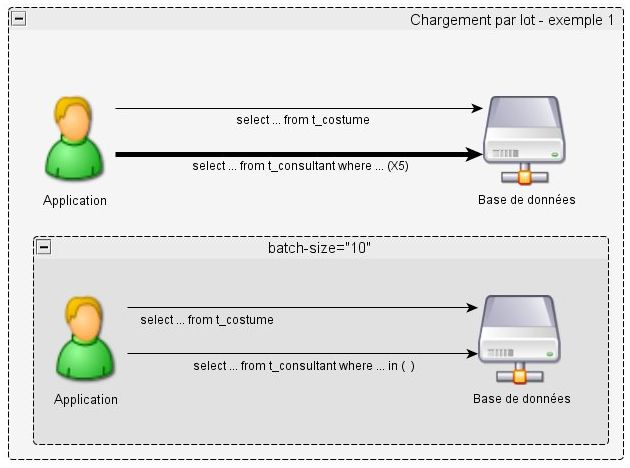
}VII-A-1-c. Chargement par lot▲
Hibernate récupère un lot d'instances en un seul SELECT en spécifiant une liste de clé primaire ou de clé étrangère.
Le paramètre batch-size peut se positionner au niveau de la classe comme vu précédemment ou au niveau des collections.
VII-A-1-c-i. Exemple 5 : Récupération du propriétaire pour chaque costume▲
Prenons un exemple pour voir son utilité :
Query query = session.createQuery("from TCostume");
Iterator it = query.list().iterator();
while (it.hasNext()) {
TCostume costume = (TCostume) it.next();
System.out.println(costume.getIdCostume() + " : " + costume.getTConsultant().getNom());
}On aura six requêtes SQL (une requête qui récupère la liste des costumes et cinq autres pour récupérer les noms des consultants) :
select
tcostume0_.id_costume as id1_1_,
tcostume0_.consultant_fk as consultant2_1_,
tcostume0_.couleur_fk as couleur3_1_,
tcostume0_.prix as prix1_
from
public.t_costume tcostume0_
select
tconsultan0_.id_consultant as id1_0_0_,
tconsultan0_.nom as nom0_0_,
tconsultan0_.prenom as prenom0_0_,
tconsultan0_.email as email0_0_
from
public.t_consultant tconsultan0_
where
tconsultan0_.id_consultant=?Maintenant modifions le fichier de mapping de TConsultant afin d'utiliser le chargement par lot à l'aide du paramètre batch-size :
<class name="hibernateperfarticle.TConsultant" batch-size="10" table="t_consultant" schema="public">Et nous obtenons seulement deux requêtes (une requête qui récupère la liste des costumes et une pour récupérer tous les consultants).
select
tcostume0_.id_costume as id1_1_,
tcostume0_.consultant_fk as consultant2_1_,
tcostume0_.couleur_fk as couleur3_1_,
tcostume0_.prix as prix1_
from
public.t_costume tcostume0_
select
tconsultan0_.id_consultant as id1_0_0_,
tconsultan0_.nom as nom0_0_,
tconsultan0_.prenom as prenom0_0_,
tconsultan0_.email as email0_0_
from
public.t_consultant tconsultan0_
where
tconsultan0_.id_consultant in (
?, ?, ?, ?, ?
)VII-A-1-d. Chargement par sous-select▲
Hibernate récupère les associations pour toutes les entités récupérées dans une requête dans un second SELECT.
De même que pour le chargement par jointure, il faut faire attention à ne pas se retrouver avec une requête SQL trop compliquée.
VII-A-1-d-i. Exemple 6 : Récupération de la liste des costumes par consultant▲
Toujours avec le même code afin de récupérer la liste des costumes par consultant :
List<TConsultant> list = session.createQuery("from TConsultant").list();
for (TConsultant consultants : list) {
Set sets = consultants.getTCostumes();
for (Iterator iter = sets.iterator(); iter.hasNext();) {
TCostume costume = (TCostume) iter.next();
System.out.println(consultants.getNom()+" "+costume.getIdCostume());
}
}On aura 6 requêtes SQL (une pour récupérer la liste des consultants, puis une par consultant afin de récupérer ses costumes) :
select
tconsultan0_.id_consultant as id1_0_,
tconsultan0_.nom as nom0_,
tconsultan0_.prenom as prenom0_,
tconsultan0_.email as email0_
from
public.t_consultant tconsultan0_
select
tcostumes0_.consultant_fk as consultant2_1_,
tcostumes0_.id_costume as id1_1_,
tcostumes0_.id_costume as id1_1_0_,
tcostumes0_.consultant_fk as consultant2_1_0_,
tcostumes0_.couleur_fk as couleur3_1_0_,
tcostumes0_.prix as prix1_0_
from
public.t_costume tcostumes0_
where
tcostumes0_.consultant_fk=?Maintenant activons le chargement par sous-select dans le fichier TConsultant.hbm.xml :
<set name="TCostumes" inverse="true" fetch="subselect">Il ne reste plus que deux requêtes SQL :

select
tconsultan0_.id_consultant as id1_0_,
tconsultan0_.nom as nom0_,
tconsultan0_.prenom as prenom0_,
tconsultan0_.email as email0_
from
public.t_consultant tconsultan0_
select
tcostumes0_.consultant_fk as consultant2_1_,
tcostumes0_.id_costume as id1_1_,
tcostumes0_.id_costume as id1_1_0_,
tcostumes0_.consultant_fk as consultant2_1_0_,
tcostumes0_.couleur_fk as couleur3_1_0_,
tcostumes0_.prix as prix1_0_
from
public.t_costume tcostumes0_
where
tcostumes0_.consultant_fk in (
select
tconsultan0_.id_consultant
from
public.t_consultant tconsultan0_
)VII-A-2. Quand l'association est chargée▲
VII-A-2-a. Chargement tardif▲
Une collection est chargée lorsque l'application invoque une méthode sur cette collection (il s'agit du mode de chargement par défaut pour les collections).
Reprenons le même exemple que précédemment :
TConsultant consultant = (TConsultant) session.get(TConsultant.class, 4108);
Set sets = consultant.getTCostumes();
for (Iterator iter = sets.iterator(); iter.hasNext();) {
TCostume costume = (TCostume) iter.next();
System.out.println(costume.getIdCostume());
}Activons les bons logs.
Comme il est indiqué dans les logs, on ne charge dans un premier temps que les informations du consultant :
/* load hibernatep.TConsultant */
select
tconsultan0_.id_consultant as id1_2_0_,
tconsultan0_.nom as nom2_0_,
tconsultan0_.prenom as prenom2_0_,
tconsultan0_.email as email2_0_
from
public.t_consultant tconsultan0_
where
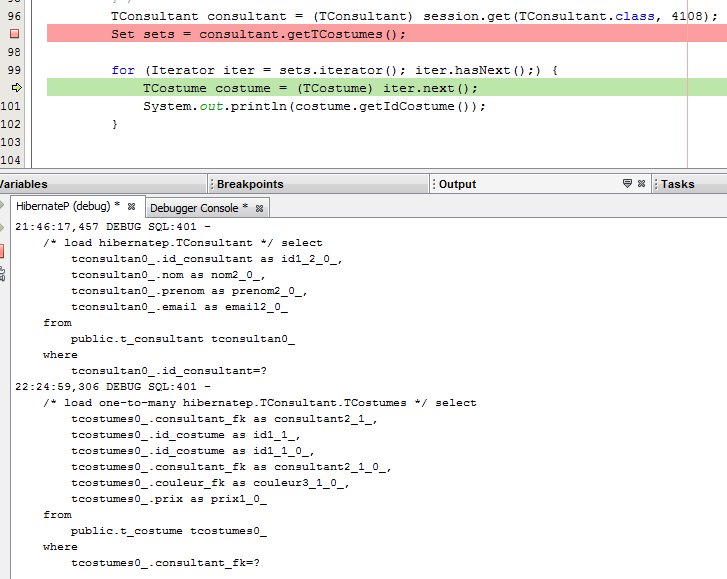
tconsultan0_.id_consultant=?Puis dans un 2e temps seulement, les informations de ses costumes :
/* load one-to-many hibernatep.TConsultant.TCostumes */
select
tcostumes0_.consultant_fk as consultant2_1_,
tcostumes0_.id_costume as id1_1_,
tcostumes0_.id_costume as id1_1_0_,
tcostumes0_.consultant_fk as consultant2_1_0_,
tcostumes0_.couleur_fk as couleur3_1_0_,
tcostumes0_.prix as prix1_0_
from
public.t_costume tcostumes0_
where
tcostumes0_.consultant_fk=?Mettons un point d'arrêt avant la récupération des costumes et lançons le programme en mode debug.
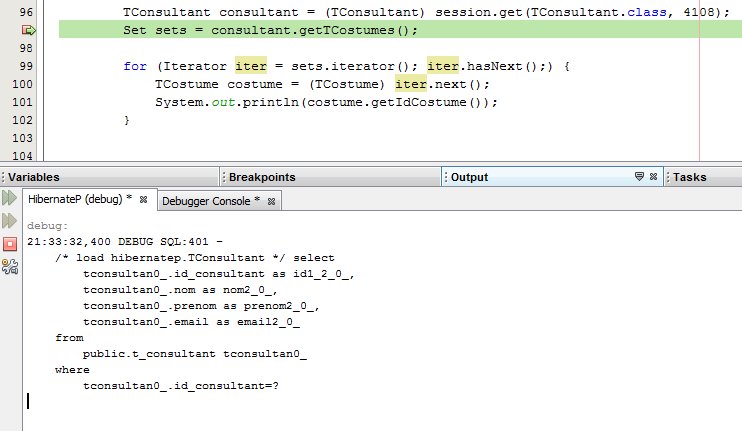
Comme on peut le voir, la 2e requête SQL n'est pas exécutée.
Puis lorsqu'on a besoin des informations des costumes, la requête SQL est exécutée.
VII-A-2-b. Chargement immédiat▲
Une association, une collection ou un attribut est chargé immédiatement lorsque l'objet auquel appartient cet élément est chargé.
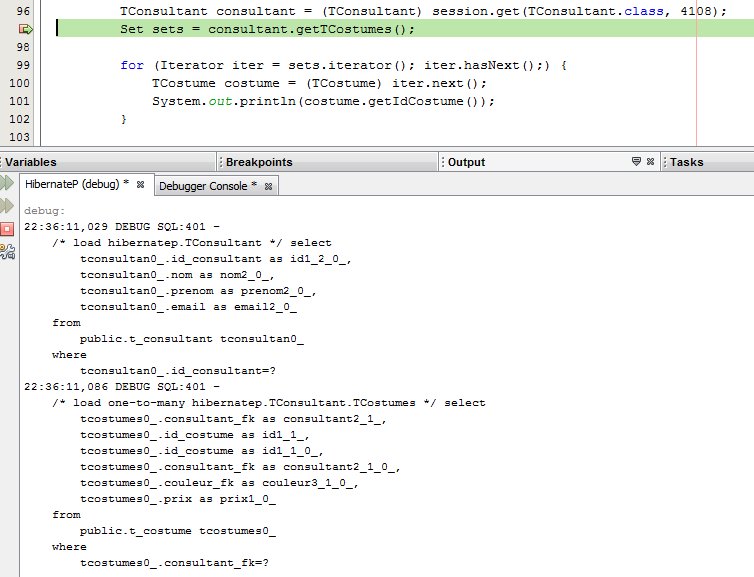
Refaisons la même chose que précédemment, mais en ajoutant le paramètre lazy=« false » à l'association concernée :
<set name="TCostumes" inverse="true" lazy="false">Et là, on voit bien que les deux requêtes sont exécutées directement.
Afin de bien le confirmer, on exécute le code suivant tout seul en commentant les autres lignes :
TConsultant consultant = (TConsultant) session.get(TConsultant.class, 4108);On obtient bien les deux mêmes requêtes.
Donc si on n'a pas besoin des détails des costumes, le chargement immédiat est pénalisant, car il va exécuter une requête qui ne sert à rien.
Par contre dans le cas contraire, cela revient au même, car on aura les deux mêmes requêtes SQL. Si on ne veut qu'une seule requête qui récupère toutes les informations, il faut utiliser le chargement par jointure comme vu précédemment.
Donc le chargement immédiat est à utiliser avec précaution, car on peut se retrouver avec énormément de requêtes SQL exécutées alors que seule la 1re est utile.
On verra plus loin avec une volumétrie plus importante que cela peut poser de gros problème. Mais avant cela, ajoutons un chargement immédiat entre TCouleur et TCostumes et exécutons le même code que celui de la partie « chargement tardif ».
<many-to-one name="TCouleur" class="hibernatep.TCouleur" fetch="select" lazy="false">Cette fois-ci on obtient beaucoup plus de requêtes SQL, car pour chaque costume on récupère sa couleur :
/* load hibernatep.TConsultant */ select
tconsultan0_.id_consultant as id1_2_0_,
tconsultan0_.nom as nom2_0_,
tconsultan0_.prenom as prenom2_0_,
tconsultan0_.email as email2_0_
from
public.t_consultant tconsultan0_
where
tconsultan0_.id_consultant=?
/* load one-to-many hibernatep.TConsultant.TCostumes */ select
tcostumes0_.consultant_fk as consultant2_1_,
tcostumes0_.id_costume as id1_1_,
tcostumes0_.id_costume as id1_1_0_,
tcostumes0_.consultant_fk as consultant2_1_0_,
tcostumes0_.couleur_fk as couleur3_1_0_,
tcostumes0_.prix as prix1_0_
from
public.t_costume tcostumes0_
where
tcostumes0_.consultant_fk=?
/* load hibernatep.TCouleur */ select
tcouleur0_.id_couleur as id1_0_0_,
tcouleur0_.nom_couleur as nom2_0_0_
from
public.t_couleur tcouleur0_
where
tcouleur0_.id_couleur=?
/* load hibernatep.TCouleur */ select
tcouleur0_.id_couleur as id1_0_0_,
tcouleur0_.nom_couleur as nom2_0_0_
from
public.t_couleur tcouleur0_
where
tcouleur0_.id_couleur=?
/* load hibernatep.TCouleur */ select
tcouleur0_.id_couleur as id1_0_0_,
tcouleur0_.nom_couleur as nom2_0_0_
from
public.t_couleur tcouleur0_
where
tcouleur0_.id_couleur=?Je vous laisse imaginer sur une forte volumétrie.
VII-A-2-c. Chargement « super tardif » d'une collection▲
Comme pour le chargement tardif, mais en plus intelligent, car les éléments de la collection sont récupérés individuellement depuis la base de données lorsque cela est nécessaire. De plus certaines fonctions comme size(), contains(), get()… ne déclencheront pas de requête SQL supplémentaire.
La différence de performance ne se verra que sur les très grosses collections et/ou lors de l'utilisation d'une des fonctions précédentes.
Le chargement « super tardif » se paramètre avec lazy=« extra ».
Prenons comme exemple ce code :
TConsultant consultant = (TConsultant) session.get(TConsultant.class, 4108);
System.out.println(consultant.getTCostumes().size());Avec un chargement tardif, on aura deux requêtes SQL :
/* load hibernatep.TConsultant */ select
tconsultan0_.id_consultant as id1_2_0_,
tconsultan0_.nom as nom2_0_,
tconsultan0_.prenom as prenom2_0_,
tconsultan0_.email as email2_0_
from
public.t_consultant tconsultan0_
where
tconsultan0_.id_consultant=?
/* load one-to-many hibernatep.TConsultant.TCostumes */ select
tcostumes0_.consultant_fk as consultant2_1_,
tcostumes0_.id_costume as id1_1_,
tcostumes0_.id_costume as id1_1_0_,
tcostumes0_.consultant_fk as consultant2_1_0_,
tcostumes0_.couleur_fk as couleur3_1_0_,
tcostumes0_.prix as prix1_0_
from
public.t_costume tcostumes0_
where
tcostumes0_.consultant_fk=?Une fois en mode « super tardif », on aura toujours deux requêtes SQL, mais la 2e sera plus « légère » :
<set name="TCostumes" inverse="true" lazy="extra"> /* load hibernatep.TConsultant */ select
tconsultan0_.id_consultant as id1_2_0_,
tconsultan0_.nom as nom2_0_,
tconsultan0_.prenom as prenom2_0_,
tconsultan0_.email as email2_0_
from
public.t_consultant tconsultan0_
where
tconsultan0_.id_consultant=?
select
count(id_costume)
from
public.t_costume
where
consultant_fk =?VII-A-2-d. Chargement tardif des attributs▲
C'est la même chose que le chargement tardif, mais pour un attribut. Cela peut être utile si une classe persistante contient énormément de propriétés ou quelques propriétés volumineuses (un long texte…).
Pour l'utiliser il faut ajouter lazy=« true » à un attribut et d'activer l'instrumentation du bytecode par Hibernate.
Une autre solution est d'utiliser les projections pour ne charger que les attributs que l'on veut.
Par exemple avec l'API Criteria, pour ne charger que l'identifiant et le nom des consultants :
List listeId = session.createCriteria(TConsultant.class).
setProjection( Projections.projectionList()
.add(Projections.property("idConsultant"))
.add(Projections.property("nom")))
.list();donnera en SQL :
/* criteria query */ select
this_.id_consultant as y0_,
this_.nom as y1_
from
public.t_consultant this_La même chose est possible en HQL :
Query query = session.createQuery("select idConsultant,nom from TConsultant");VII-B. Exemples avec une plus grosse volumétrie▲
Maintenant reprenons deux exemples précédemment étudiés, mais cette fois-ci avec une volumétrie plus importante afin d’observer le gain potentiel d'un bon paramétrage d'Hibernate.
Pour changer de volumétrie, il suffit de changer la valeur des paramètres « count » dans notre fichier projet de Benerator.
Pour avoir 1000 de consultants :
<generate type="t_consultant" count="1000" consumer="db" pageSize="1000" >Et 3000 de costumes :
<generate type="t_costume" count="3000" consumer="db" pageSize="1000">On se retrouve assez rapidement avec une base de données rempli.
VII-B-1. Exemple 7 : Chargement par lot▲
Reprenons l'exemple utilisé lors de la partie « Chargement par lot » et exécutons-le avec les paramètres par défaut de Hibernate (chargement par select et tardif).
Comme prévu, on se retrouve avec 1001 requêtes SQL.
En modifiant le fichier de mapping de TConsultant afin d'utiliser le chargement par lot à l'aide du paramètre batch-size, il ne reste plus que 11 requêtes SQL :
<class name="hibernateperfarticle.TConsultant" batch-size="100" table="t_consultant" schema="public">VII-B-2. Exemple 8 : Chargement par sous-select▲
Maintenant ré exécutons l'exemple utilisé lors de la partie « Chargement par sous-select » et exécutons-le avec les paramètres par défaut de Hibernate (chargement par select et tardif).
Comme prévu, on se retrouve avec 1001 requêtes SQL.
Maintenant activons le chargement par sous-select dans le fichier TConsultant.hbm.xml afin de n'avoir plus que deux requêtes SQL :
<set name="TCostumes" inverse="true" fetch="subselect">VII-B-3. Exemple 9 : Exemple à très forte volumétrie▲
Pour les plus courageux et ceux qui veulent prendre de l'avance sur l'un des prochains articles sur Hibernate, ils peuvent essayer avec cette volumétrie.
1 000 000 de consultants :
<generate type="t_consultant" count="1000000" consumer="db" pageSize="1000" >5 000 000 de costumes :
<generate type="t_costume" count="3000000" consumer="db" pageSize="1000">Attention, il faut laisser un peu de temps à Benerator pour générer cette volumétrie (sur ma machine, il génère environ 4 600 000 lignes par heure).
VII-C. Conclusion▲
Comme on a pu le voir, un paramétrage plus fin des stratégies de chargement d'Hibernate permet d'optimiser notre application en réduisant le nombre de requêtes SQL générées.
Mais il faut faire attention, car réduire le nombre de requêtes SQL n'est pas toujours la meilleure solution si on se retrouve avec des requêtes trop complexes et consommatrices. En effet la 2e piste d'optimisation est la gestion des caches de Hibernate qu'il faudra combiner avec la gestion des stratégies de chargement. C'est ce que nous verrons lors du prochain article consacré à Hibernate.
VII-D. Remerciements▲
Merci à ram-0000 pour sa relecture orthographique.
VII-E. Références▲
Documentation officielle : http://www.hibernate.org/docs.html
Documentation sur dvp.com : https://java.developpez.com/cours/?page=persistance-cat#hibernate
Site officiel de Benerator : http://databene.org/databene-benerator