




I. Introduction▲
Lors d'un audit de performance d'une application, il est important de le faire avec un système le plus proche de l'environnement de production. Pour cela il faut que l'environnement de test (souvent l'environnement de préproduction) ait le même matériel, logiciel, paramètres de configuration et jeu de données que l'environnement de production. C'est sur ce dernier point que nous allons nous concentrer.
Nous verrons comment utiliser Benerator pour créer un jeu de données de test pour un tir de charge. Benerator étant très riche en fonctionnalités (la documentation fait 100 pages), nous allons donc nous focaliser sur :
- comment rendre anonymes les données existantes de production ;
- la création d'un jeu de données à partir de rien.
II. Problématiques des jeux de données de test▲
La première idée qui nous vient à l'esprit est d'utiliser les données existantes de production, mais cela pose un certain nombre de problèmes :
- données sensibles ;
- données inexistantes, car l'application n'est pas encore finie ;
- données incomplètes (nouvelle version de l'application avec un périmètre plus large…) ;
- données de mauvaise qualité ou trop anciennes.
Et donc la plupart du temps, il faudra travailler les données pour qu'elles soient exploitables.
III. Provenances des données▲
Regardons d'un peu plus près l'origine des données que nous pouvons utiliser lors d'un test de charge.
III-A. Données de production▲
Si les données de production sont exploitables, il est judicieux de les utiliser directement s'il n'y a pas de problème de confidentialité. Plusieurs solutions sont possibles afin de les transférer sur l'environnement de test.
En particulier :
- les ETL ;
- l'import/export à l'aide d'outils de migration ou de dumps.
- …
Nous étudierons plus loin comment utiliser ces données afin de les rendre exploitables pour un test de charge.
III-B. Données générées par script▲
Une autre solution est de créer des scripts de génération de données.
Ces scripts peuvent prendre la forme de :
- requêtes SQL d'insertion ;
- …
Le gros avantage des scripts est que l'on peut contrôler exactement les données qui seront utilisées. Malheureusement dans le cas d'un test de charge, il faut énormément de données et donc cela peut être fastidieux de créer et de maintenir ces scripts.
Cette solution ne sera pas étudiée.
III-C. Données créées par des générateurs▲
La dernière solution est d'utiliser des outils pour la création du jeu de données de test.
Si l'outil est bien choisi, cela résoudra une partie des problèmes liés à la solution précédente. Par exemple, il sera aussi simple de générer peu de données comme plusieurs millions de données.
Par contre on perdra un peu le contrôle sur les données.
Penchons-nous maintenant sur cette solution avec l'outil Benerator.
IV. Présentation de Benerator▲
Nous allons étudier Benerator qui est un outil créé par Volker Bergmann en 2006 sous la double licence GPL et commercial.
Depuis sa création, de nouvelles versions se sont succédé (la version 1.0 est prévue pour la fin de l'année de 2010).
Attention, car il faut Java 6 pour le faire fonctionner.
IV-A. Fonctionnalités▲
Voici un tour d'horizon de ces fonctionnalités :
- génération de données de test ;
- rendre anonymes des données de production ;
- insérer des données dans la base de données ;
- création de fichiers de données.
IV-B. Ses atouts▲
Benerator a de nombreux atouts comme on le verra plus loin, mais en voilà une liste :
- configurable afin de s'adapter à un maximum de situations ;
- extensible ;
- multiplateformes ;
- plugin pour Eclipse ;
- plugin pour Maven2 ;
- bonne documentation en anglais ;
- activement développé ;
- gratuit ;
- maintenance simple une fois la phase de démarrage réalisée ;
- des domaines (adresse, finance, web…) pour les données afin qu'elles soient réalistes ;
- supporte la majorité des bases de données du marché ;
- …
IV-C. Fonctionnement de Benerator▲
Voici un schéma simplifié du fonctionnement de Benerator.
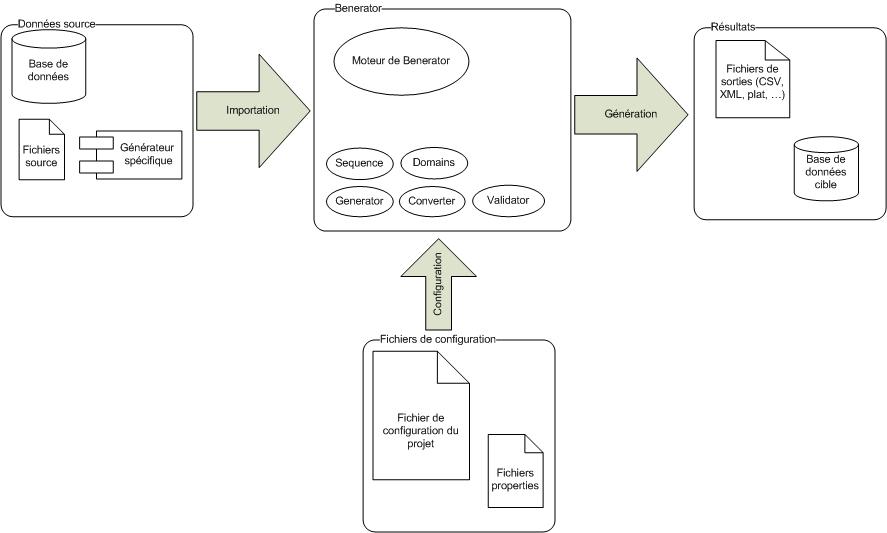
Le processus de la création du jeu de données est assez simple :
- Benerator lit les fichiers de configuration du projet ;
- Benerator importe les données des sources (base de données, fichier (XML, DBunit, CSV…) si cela est demandé dans le fichier de configuration du projet ;
- Benerator traite le fichier de configuration en faisant appel à ces divers modules s'ils sont utilisés ;
- Benerator exporte les données créées dans le format cible qui a été configuré (base de données, fichier…).
V. Installation▲
Regardons comment installer Benerator et ses plugins afin de faciliter son utilisation.
V-A. Installation de Benerator▲
L'installation est assez simple, il suffit de :
- télécharger le binaire ;
- le dézipper ;
- créer la variable d'environnement BENERATOR_HOME qui pointe sur le répertoire d'installation ;
- installer le driver JDBC si nécessaire (des drivers JDBC open source sont intégrés par défaut).
Et pour le lancer il suffit d'appeler la commande benerator.bat avec le nom du fichier XML de configuration du projet.
V-B. Plugin Eclipse▲
Il existe un plugin pour Eclipse qui permet de simplifier l'utilisation de Benerator à l'aide d'assistants.
Il est aussi sous double licence : GPL et commercial.
Pour l'installer il suffit d'ajouter dans Eclipse update le site: http://databene.org/eclipse/updates/

Une fois l'installation faite, on se retrouve avec une nouvelle icône dans la barre d'icônes d'Eclipse.
Avec de nouveaux assistants.
En particulier pour la configuration de JDBC.
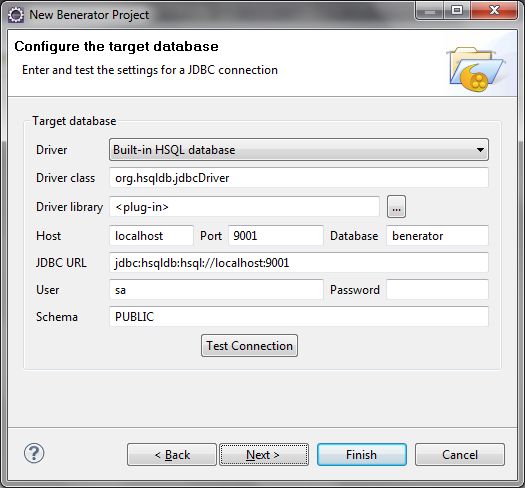
Une fois le projet créé, on peut lancer Benerator.
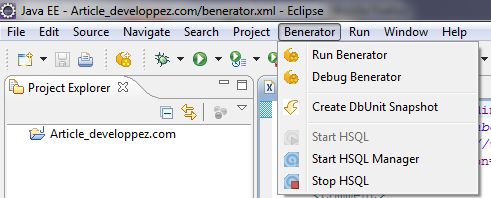
De plus un outil de sauvegarde de la base de données au format DBUnit et une base de données HSQL pour les tests sont fournis.
V-C. Plugin Maven▲
En plus du plugin d'Eclipse, il existe un plugin Maven afin d'ajouter Benerator au cycle de vie de votre projet.
Les prérequis sont au minimum Maven 2.0.8 et le JDK 1.6.
Ce plugin comprend trois cibles/goals qui sont :
- benerator:createxml : Créer un fichier XML à partir d'un fichier XML Schema ;
- benerator:dbsnapshot : Créer un dump de la base au format DbUnit ;
- benerator:generate : Exécuter Benerator.
Regardons d'un peu plus près comment intégrer Benerator à un projet Maven.
Il suffit d'ajouter ceci dans son pom.xml
<build>
...
<plugins>
<plugin>
<groupId>org.databene</groupId>
<artifactId>maven-benerator-plugin</artifactId>
<version>0.6</version>
<configuration>
<descriptor>src/test/benerator/myproject.ben.xml</descriptor>
<encoding>iso-8859-1</encoding>
<dbDriver>oracle.jdbc.driver.OracleDriver</dbDriver>
<dbUrl>jdbc:oracle:thin:@localhost:1521:XE</dbUrl>
<dbSchema>user</dbSchema>
<dbUser>user</dbUser>
<dbPassword>password</dbPassword>
</configuration>
<dependencies>
<dependency>
<groupId>oracle</groupId>
<artifactId>ojdbc</artifactId>
<version>1.4</version>
</dependency>
</dependencies>
<executions>
<execution>
<phase>integration-test</phase>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>Les options de configuration sont les suivantes :
- descriptor : le chemin du fichier de description de Benerator ;
- encoding : l'encodage utilisé par défaut ;
- validate : activer la validation (XML et data model) ;
- dbDriver : le driver JDBC ;
- dbUrl : URL du driver JDBC ;
- dbSchema : le schéma de la base de données à utiliser ;
- dbUser : le login de la base de données ;
- dbPassword : le mot de passe de la base de données.
L'ajout de dépendances (Maven 2.0.9 minimum) externes au projet (non présent dans le classpath) se fait dans la partie <dependencies> </dependencies>.
Pour ajouter Benerator à une étape particulière du cycle de vie du projet, paramétrer la partie <executions> </executions>.
Par exemple ici, la cible « generate » de Benerator sera exécutée à chaque lancement des tests d'intégration.
Plus d'informations sur http://databene.org/maven-benerator-plugin.html
V-D. DB Snapshot Tool▲
DbSnaphotTool permet de créer un snapshot du schéma de la base de données dans un fichier au format DbUnit XML. Cet outil est aussi intégré dans le plugin Eclipse comme on peut le voir sur cette capture d'écran.
VI. Utilisations de Benerator▲
Maintenant que Benerator est installé, regardons comment l'utiliser.
VI-A. Création du fichier XML de description du projet▲
La configuration du projet se passe dans un fichier XML de description.
Dans ce fichier, il y a
- un entête
<?xml version="1.0" encoding="iso-8859-1"?>
<setup xmlns="http://databene.org/benerator/0.6.3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://databene.org/benerator/0.6.3 http://databene.org/benerator-0.6.3.xsd">
....
</setup>- un bloc pour chaque table.
<generate>
</generate>Ou
<iterate>
</iterate>- à l'intérieur il y a un bloc pour tous les champs de la table.
<attribute>
</attribute>- et au moins une balise
qui indique le format de sortie (fichier plat, fichier XML, bdd…).
<consumer>VI-A-1. Attribut d'un champ de la table▲
Comme il a été dit précédemment, les champs d'une table sont décrits avec la balise <attribute>.
La balise <attribute> a de nombreux paramètres afin de s'adapter à toutes les situations.
Commençons par donner un nom au champ avec le paramètre name de la manière suivante.
<attribute name="nom" />Regardons maintenant d'autres paramètres.
VI-A-1-a. Type du champ▲
On peut définir le type du champ à l'aide du paramètre « type ».
Par exemple :
<attribute name="nom" type="string"/>
<attribute name="prix" type="big_decimal" />Par défaut si ce n'est pas indiqué, cela sera une chaine de caractère.
Voilà la liste des types possibles.
|
Benerator type |
JDBC type |
Java type |
|---|---|---|
|
byte |
Types.BIT |
java.lang.Byte |
|
byte |
Types.TINYINT |
java.lang.Byte |
|
short |
Types.SMALLINT |
java.lang.Short |
|
int |
Types.INTEGER |
java.lang.Integer |
|
big_integer |
Types.BIGINT |
java.math.BigInteger |
|
float |
Types.FLOAT |
java.lang.Float |
|
double |
Types.DOUBLE |
java.lang.Double |
|
double |
Types.NUMERIC |
java.lang.Double |
|
double |
Types.REAL |
java.lang.Double |
|
big_decimal |
Types.DECIMAL |
java.math.BigDecimal |
|
boolean |
Types.BOOLEAN |
java.lang.Boolean |
|
char |
Types.CHAR |
java.lang.Character |
|
date |
Types.DATE |
java.lang.Date |
|
timestamp |
Types.TIMESTAMP |
java.lang.Timestamp |
|
string |
Types.VARCHAR |
java.lang.String |
|
string |
Types.LONGVARCHAR |
java.lang.String |
|
string |
Types.CLOB |
java.lang.String |
|
object |
Types.JAVA_OBJECT |
java.lang.Object |
|
binary |
Types.BINARY |
byte[] |
|
binary |
Types.VARBINARY |
byte[] |
|
binary |
Types.BLOB |
byte[] |
VI-A-1-b. Valeur du champ▲
Maintenant, ajoutons-lui une valeur.
Il existe plusieurs solutions.
- Valeurs venant d'une liste contenue dans le paramètre values ou pattern
La manière la plus simple est d'utiliser le paramètre values qui attend une liste de valeurs séparées par une virgule.
<attribute name="nom" values="'Pierre','Paul'" />L'utilisation du paramètre pattern est une autre solution.
<attribute name="couleur" pattern="(rouge|vert)" />- Valeurs générées à partir d'une expression régulière avec le paramètre pattern
Pour générer des valeurs à partir de rien, il est possible d'utiliser le paramètre pattern qui utilise des expressions régulières afin de contrôler ce qui est généré.
Par exemple :
<attribute name="nom" pattern="[0-9]{10-15}" /><attribute name="password" pattern="[A-Za-z0-9]{8,12}" />On peut aussi limiter la taille de la chaine de caractères générée avec les paramètres minLength et maxLength.
- Valeurs générées à partir d'un ou plusieurs autres attributs de la même table avec this
Pour générer des valeurs à partir d'autres attributs du même objet, il est possible d'utiliser this comme en Java pour faire référence à un autre attribut du même objet.
Par exemple :
<generate name="Telephone">
<attribute name="Indicatif" pattern="[0-9]{3}"
<attribute name="Tel" pattern="[0-9]{7}/>
<attribute name="TelComplet" script="'+' + this.Indicatif + this.Tel" />
</generate>- Valeurs importées depuis une source avec le paramètre source
On peut importer les valeurs à partir de fichiers, d'une table.
Voici quelques exemples :
<iterate type="nom" source="noms.import.flat" pattern="name[30],firstname[30]" consumer="db" /><database id="db" url="jdbc:hsqldb:hsql://localhost" driver="org.hsqldb.jdbcDriver" user="sa" />
...
<attribute name="nom" source="db" selector="select nom from db_noms" distribution="random" /><attribute name="sexe" source="db" selector="select sexe from T_Client" distribution="random"
script="{ftl:[#ftl][#if Nom_De_La_Table.sexe='1']M[#else]F[/#if]}" /><iterate type="nom" source="noms.import.csv" encoding="utf-8" consumer="db" />Il est possible lors de l'importation de données à partir d'un fichier CSV, de définir la distribution des données avec le paramètre « distribution » égal à « weighted ».
Par exemple pour avoir 70 % de personnes qui s'appellent Pierre et 30 % qui s'appellent Paul.
nom,pourcentage
Pierre,7
Paul,3<iterate type="noms" source="noms.import.csv" count="100" encoding="utf-8"
distribution="weighted[pourcentage]" consumer="db" />
<id name="id" type="long" />
<attribute name="nom" script="noms.nom"/>
</iterate>- Valeurs importées depuis une source avec le paramètre source et modifiées par le paramètre converter
On pourra faire des traitements (mettre en majuscule, remplacer une valeur par une autre, convertir une date en chaine de caractère…) grâce au paramètre converter.
Par exemple :
<attribute name="nom" source="db" selector="select nom from db_noms" distribution="random"
converter="org.databene.commons.converter.CaseConverter" /><attribute name="nom" source="db" selector="select nom from db_noms" distribution="random"
converter="org.databene.commons.converter.NameNormalizer" />De nombreux autres converters existent et on peut en créer d'autres assez facilement.
- Valeurs null avec le paramètre nullable
Il suffit de paramétrer nullable à true.
<attribute name="age" nullable="true" />- Valeurs issues des « domains » de Benerator
Il existe dans Benerator des « générateurs » de valeurs réalistes appelés domains.
Il y a six domains inclus par défaut dans Benerator (bien sûr il est possible d'en créer d'autres).
|
Nom du domain |
Description |
|---|---|
|
person |
Données relatives à une personne (nom, prénom…) |
|
address |
Données relatives à une adresse (ville, code postal…) |
|
net |
Nom de domaine et adresse mail |
|
finance |
Données relatives au domaine bancaire (numéro de carte bleu…) |
|
organization |
Nom de compagnies |
|
product |
Code EAN d'un produit |
L'utilisation d'un domain est assez simple, il suffit de l'importer à l'aide de la balise import et de l'utiliser.
Il faut faire attention, car tous les domains ne sont pas localisés en français (s’ils le sont, ajoutez dataset=« FR » locale=« fr »).
Par exemple pour la création d'une table Clients.
<?xml version="1.0" encoding="iso-8859-1"?>
<setup xmlns="http://databene.org/benerator/0.6.3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://databene.org/benerator/0.6.3 http://databene.org/benerator-0.6.3.xsd">
<import defaults = "true"
domains = "person,net,finance,organization,address"
platforms = "db"/>
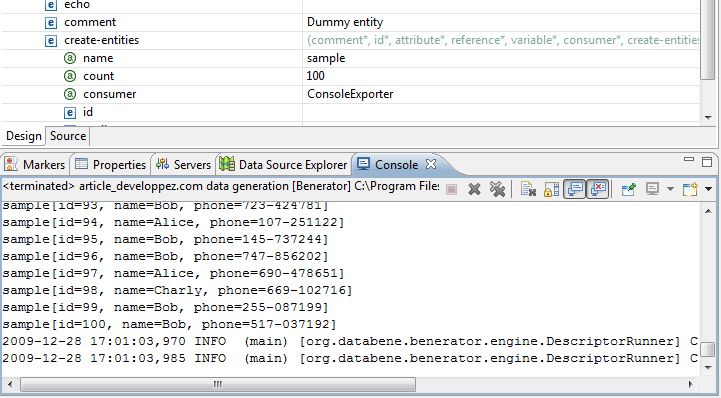
<generate name="Clients" count="5" consumer="org.databene.model.consumer.ConsoleExporter">
<variable name="individu" generator="PersonGenerator" dataset="FR" locale="fr"/>
<variable name="adresse" generator="AddressGenerator" />
<attribute name="sex" script="individu.gender" />
<attribute name="salutation" script="individu.salutation" />
<attribute name="prenom" script="individu.givenName" />
<attribute name="nom" script="individu.familyName" />
<attribute name="date_naissance" script="individu.birthDate" />
<attribute name="mail" script="individu.email" />
<attribute name="telephone_mobile" script="adresse.mobilePhone" />
<attribute name="telephone_fixe" script="adresse.privatePhone" />
<attribute name="telephone_pro" script="adresse.officePhone" />
<attribute name="fax" script="adresse.fax" />
<attribute name="numero_de_rue" script="adresse.houseNumber" />
<attribute name="rue" script="adresse.street" />
<attribute name="code_postal" script="adresse.postalCode" />
<attribute name="ville" script="adresse.city" />
<attribute name="pays" script="adresse.country" />
<attribute name="employeur" generator="CompanyNameGenerator" dataset="DE" locale="de_DE"/>
<attribute name="numero_CB" generator="CreditCardNumberGenerator" />
</generate>
</setup>Donnera des lignes du type.
entity[sex=MALE, salutation=M., prenom=Henri, nom=Leroy, date_naissance=1942-04-07T01:50:39,
mail=henri.leroy@david-roux.com, telephone_mobile=+1--3552961, telephone_fixe=+1-931-211121, telephone_pro=+1-931-785264, fax=+1-931-467191,
numero_de_rue=21, rue=Lincoln Street, code_postal=38425, ville=CLIFTON, pays=United States,
employeur=FWY GmbH,
numero_CB=4640100863494684]Si on veut contrôler la date de naissance, on peut le faire de la manière suivante depuis la version 0.6.3 de Benerator.
<attribute name="date_naissance" generator="new BirthDateGenerator(minAgeYears=20, maxAgeYears=40)"/>Nous aurons des personnes ayant un âge compris entre 20 et 40 ans.
- Valeurs issues de générateurs créés par l'utilisateur
Pour cela, il faut définir la classe java (qui doit être dans le classpath) à l'aide de la balise <bean>.
<bean id="couleur_generator" class="CouleurGenerator">
<property name="unique" value="true" />
</bean>Puis l'utiliser avec le paramètre source de la balise <attribute>.
<generate name="T_couleurs" >
<attribute name="code_couleur" source="couleur_generator" unique="true"/>
</generate>- Valeur définie par défaut avec la balise
On peut configurer à l'aide de la balise <defaultComponents> des valeurs par défaut pour les colonnes des tables.
Par exemple :
<defaultComponents>
<attribute name="CREATED_AT" generator="CurrentDateGenerator"/>
<attribute name="CREATED_BY" constant="benerator"/>
<attribute name="UPDATED_AT" generator="CurrentDateGenerator"/>
<attribute name="UPDATED_BY" constant="benerator"/>
</defaultComponents>Dans cet exemple, si ces colonnes ne sont pas configurées (à l'aide des méthodes précédemment citées), elles seront automatiquement remplies.
Dans tous les cas si on veut que la valeur du champ soit unique, il suffit d'utiliser le paramètre unique (unique = « true »). Attention, car on est limité à 100 000 éléments, car tout se déroule en mémoire.
Regardons d'un peu plus près les champs de type date et nombre.
VI-A-1-b-i. Date et nombre▲
Pour ces deux types, des paramètres supplémentaires existent.
- Paramétrer le minimum d'une date ou d'un nombre avec le paramètre « min »
<attribute name="date_creation" min="2009-01-01" />
<attribute name="prix" type="big_decimal" min="0.99" />- Paramétrer le maximum d'une date ou d'un nombre avec le paramètre « max »
<attribute name="prix" type="big_decimal" max="99.99" />- Paramétrer la précision d'une date ou d'un nombre avec le paramètre « precision »
<attribute name="prix" type="big_decimal" min="0.99" max="99.99" precision="0.10" />VI-A-1-c. Clé primaire et clé étrangère▲
Maintenant que nous avons créé les tables et ses attributs, regardons comment définir les clés primaires et les clés étrangères.
VI-A-1-c-i. Clé primaire▲
Les clés primaires sont générées comme des nombres entiers auto incrémentés. Pour créer une clé primaire, il faut utiliser la balise <id> et définir sa stratégie de génération avec le paramètre generator.
Par exemple :
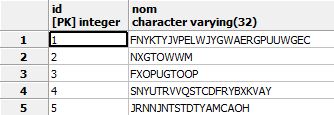
<generate type="Clients" count="5" consumer="org.databene.model.consumer.ConsoleExporter">
<id name="ID" type="long" generator="org.databene.benerator.primitive.IncrementalIdGenerator" />
<attribute name="nom" />
</generate>a pour résultat :
Les stratégies de génération sont :
|
Nom |
Description |
|---|---|
|
IncrementalIdGenerator |
La valeur de la clé sera automatiquement incrémentée. |
|
DBSequenceGenerator |
La valeur de la clé sera récupérée d'une séquence issue de la base de données. |
|
DBSeqHiLoGenerator |
La valeur de la clé sera récupérée d'une séquence issue de la base de données, mais de manière beaucoup plus performante qu’avec la solution « sequence ». |
|
OfflineSequenceGenerator |
Récupère la valeur de la séquece en base et travaille offline après et fait un commit en base à la fin |
|
QueryGenerator |
La valeur de la clé sera le résultat d'une requête SQL. |
|
QueryHiLoGenerator |
Marche comme pour DBSeqHiLoGenerator, mais avec le résultat d'une requête SQL. |
Exemples d'utilisation.
<id name="ID" type="long" source="db" generator="org.databene.benerator.primitive.DBSequenceGenerator('hibernate_sequence')" />
<id name="id" generator="org.databene.platform.db.DBSeqHiLoGenerator('seq_id_gen',db)" />seq_id_gen et hibernate_sequence correspondent à deux séquences qui devront exister dans le schéma de la base de données.
Exemple pour HSQL.
<id name="id" generator="org.databene.platform.db.DBSeqHiLoGenerator('dual.seq_id_gen',db)" />Il est aussi possible d'indiquer la valeur de départ à l'aide de la syntaxe suivante.
<id name="id" type="long" generator="new IncrementalIdGenerator(100)" />Si on veut que la valeur de l'identifiant soit gérée par un champ auto-incrémenté de la base de données, on peut utiliser le paramètre mode=« ignored »
Par exemple sous PostgreSQL avec les champs de type SERIAL.
<generate type="db_user" count="50000" consumer="db" >
<id mode="ignored" />
</generate>VI-A-1-c-ii. Clé étrangère▲
Il existe plusieurs solutions pour définir les clés étrangères.
Regardons comment créer une clé étrangère entre ces deux tables.
CREATE SEQUENCE seq_id_gen;
CREATE TABLE db_couleur (
code_couleur int NOT NULL,
nom_couleur varchar(16) NOT NULL,
PRIMARY KEY (code_couleur)
);
CREATE TABLE db_costume (
code_costume int NOT NULL,
couleur_fk int NOT NULL,
PRIMARY KEY (code_costume),
CONSTRAINT db_costume_couleur_fk FOREIGN KEY (couleur_fk) REFERENCES db_couleur (code_couleur)
);- Définition d'une clé étrangère automatiquement par Benerator si c'est une relation one to one
<?xml version="1.0" encoding="iso-8859-1"?>
<setup xmlns="http://databene.org/benerator/0.6.3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://databene.org/benerator/0.6.3 http://databene.org/benerator-0.6.3.xsd">
<import platforms="db" />
<database id="db" url="jdbc:postgresql://localhost:5432/postgres" driver="org.postgresql.Driver" schema="public" user="benerator" password="benerator" />
<bean id="idGen" spec="new DBSeqHiLoGenerator('seq_id_gen', 1, db)" />
<generate type="db_couleur" count="10" consumer="db" >
<id name="code_couleur" generator="idGen" />
<attribute name="nom_couleur" values="'gris','bleu'"/>
</generate>
<generate type="db_costume" count="10" consumer="db" >
<id name="code_costume" generator="idGen" />
</generate>
</setup>- Définition d'une clé étrangère avec la balise
<?xml version="1.0" encoding="iso-8859-1"?>
<setup xmlns="http://databene.org/benerator/0.6.3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://databene.org/benerator/0.6.3 http://databene.org/benerator-0.6.3.xsd">
<import platforms="db" />
<database id="db" url="jdbc:postgresql://localhost:5432/postgres" driver="org.postgresql.Driver" schema="public" user="benerator" password="benerator" />
<bean id="idGen" spec="new DBSeqHiLoGenerator('seq_id_gen', 1, db)" />
<generate type="db_couleur" count="10" consumer="db" >
<id name="code_couleur" generator="idGen" />
<attribute name="nom_couleur" values="'gris','bleu'" />
</generate>
<generate type="db_costume" count="100" consumer="db">
<id name="code_costume" generator="idGen" />
<reference name="couleur_fk" targetType="db_couleur" source="db" distribution="random" />
</generate>
</setup>Dans cet exemple, on va créer 100 costumes qui seront répartis aléatoirement d'un point de vue couleur.
Si on veut contrôler la répartition, on peut le faire de la manière suivante :
<?xml version="1.0" encoding="iso-8859-1"?>
<setup xmlns="http://databene.org/benerator/0.6.3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://databene.org/benerator/0.6.3 http://databene.org/benerator-0.6.3.xsd">
<import platforms="db" />
<database id="db" url="jdbc:postgresql://localhost:5432/postgres" driver="org.postgresql.Driver" schema="public" user="benerator" password="benerator" />
<bean id="idGen" spec="new DBSeqHiLoGenerator('seq_id_gen', 1, db)" />
<create-entities name="db_couleur" count="10" consumer="db">
<id name="code_couleur" generator="idGen" />
<attribute name="nom_couleur" values="'gris','bleu'" />
</create-entities>
<create-entities name="db_costume" count="80" consumer="db">
<id name="code_costume" generator="idGen" />
<reference name="couleur_fk" constant="10" />
</create-entities>
<create-entities name="db_costume" count="20" consumer="db">
<id name="code_costume" generator="idGen" />
<reference name="couleur_fk" constant="15" />
</create-entities>
</setup>Ou pour avoir seulement des costumes dont le code couleur commence par le chiffre « 1 » avec l'utilisation du paramètre « selector ».
<generate name="db_costume" count="100" consumer="db">
<reference name="couleur_fk" targetType="db_couleur" source="db" selector="couleur_fk=''1%'" distribution="random"/>
</generate>- Définition d'une clé étrangère avec le paramètre « selector » de la balise
Pour un paramétrage plus manuel, lors de la création de la clé étrangère, il suffit de définir la source avec le paramètre selector.
Par exemple :
<reference name="fournisseur_id" source="db" selector="select id from db_fournisseur" cyclic="true" />
<reference name="couleur_fk" source="db" selector="select code_couleur from db_couleur" distribution="random" />Afin d'avoir une relation one to one, enlever le paramètre cyclic et/ou distribution.
VI-A-2. Update▲
Dans certains cas il peut être utile de mettre à jour une valeur d'une colonne après la création de la table.
Par exemple si la valeur d'une colonne dépend d'objets non encore remplis à l'initialisation.
C'est la balise <iterate> qu'il faut utiliser
Prenons comme exemple le prix total d'une commande.
<iterate type="db_commande" source="db" consumer="db.updater()">
<attribute name="prix_total" source="db"
selector="{{ftl:select sum(prix_total) from db_commande_item where id_commande = ${db_commande.id_commande}}}" cyclic="true"/>
</iterate>VI-A-3. Derniers paramétrages▲
Maintenant que nous avons reproduit le schéma de la base de données, il nous reste à paramétrer le volume de données qu'on veut générer et sous quelle forme (fichier, en base de données…).
VI-A-3-a. Paramétrage de la volumétrie à générer▲
Le paramétrage de la volumétrie cible est assez simple et se fait par le paramètre count de la balise <generate> lors de la création d'une table.
Par exemple.
<generate name="Individu" count="500000" consumer="db"/>Il est aussi possible d'utiliser les paramètres minCount, maxCount.
VI-A-3-a-i. Paramètres importants pour une génération rapide de notre jeu de données▲
Pour générer une forte volumétrie, il est important d'ajuster un certain nombre de paramètres afin de gagner du temps.
Dans un premier temps il faut bien choisir la stratégie de génération de la clé primaire (increment, seqhilo et uuid sont celles à préférer).
Puis faire attention à certaines limitations de Benerator (ces limitations sont des gardes fous pour limiter la dégradation de la performance).
Par exemple pour avoir une distribution aléatoire des éléments avec le paramètre random, on est limité à 100 000 éléments, car tout se passe en mémoire.
Les distributions non affectées par cette limite sont expand, randomWalk, repeat et step.
Et enfin, utiliser les paramètres pageSize, batch et fetchSize.
pageSize est le nombre de lignes qu'il y aura dans une transaction. Il est conseillé de mettre ce paramètre à 1000 pour diminuer le nombre de commit et ainsi augmenter les performances.
Il s'utilise de la manière suivante.
<generate type="t_consultant" count="1000" consumer="db" pageSize="1000" >fetchSize est le nombre de lignes récupérées en une seule fois par JDBC. Cela est utile lorsqu'une requête récupère beaucoup de lignes.
Il s'utilise lors de la définition de la base de données.
<database id="db" url="jdbc:postgresql://localhost:5432/postgres"
driver="org.postgresql.Driver" schema="public" user="benerator" password="benerator"
fetchSize="1000"/>Batch permet de faire des mises à jour groupées et est utilisé de la définition de la base de données.
<database id="db" url="jdbc:postgresql://localhost:5432/postgres"
driver="org.postgresql.Driver" schema="public" user="benerator" password="benerator"
batch="true" />VI-A-3-b. Paramétrage de la distribution des valeurs générées pour chaque champ▲
Comme on l'a déjà vu précédemment, il est possible pour chaque champ de définir la distribution des valeurs générées.
Il existe d'autres solutions que nous allons voir.
- Utilisation des fonctions mathématiques avec le paramètre distribution.
Il existe un certain nombre de fonctions mathématiques permettant de contrôler la distribution des valeurs. Bien sûr il est possible d'écrire ses propres fonctions.
Par exemple.
<import class="org.databene.benerator.distribution.function.*"/>
...
<attribute name="NoteDesEleves" type="int"
min="1" max="19"
distribution="new GaussianFunction(11,5)"/><import class="org.databene.benerator.distribution.function.*"/>
...
<attribute name="categorie" type="char" values="A,B,
distribution="new ExponentialFunction(0.5)"/>- Utilisation du paramètre nullQuota pour le pourcentage de valeur null.
<attribute name="facultatif" type="char" constant="1" nullQuota="0.9"/>- Utilisation du paramètre femaleQuota avec le domaine Person.
<variable name="individu"
generator="new PersonGenerator{dataset='FR', locale='fr', femaleQuota=0.6}" />- Définition de la distribution avec le paramètre values.
Une méthode simple est de donner le pourcentage souhaité pour chaque valeur dans le paramètre values.
Par exemple.
<attribute name="couleur" values="'noir'^50, 'bleu'^30, 'rouge'^20" />On aura pour résultat un peu près 50 % de noir, 30 % de bleu et 20 % de rouge.
Pour générer des entiers, on fera.
<attribute name="taille" type="int" values="10^75, 8^20, 5^5" />VI-A-3-c. Paramétrage de la destination▲
Avec Benerator, on peut avoir facilement le résultat de la génération sous plusieurs formes (fichier, base de données, console, JavaBeans qui implémentent l'interface Consumer…) à l'aide de l'objet Consumer.
Il y a deux façons de l'utiliser :
- par le paramètre consumer des balises ;
- par la balise à inclure dans les balises.
Regardons d'un peu plus près quelques consumers.
VI-A-3-c-i. XLS▲
<consumer class="org.databene.platform.xls.XLSEntityExporter">
<property name="uri" value="transactions.xls"/>
<property name="columns" value="id,ean_code,commentaire,prix,items"/>
</consumer>VI-A-3-c-ii. CSV▲
<consumer class="org.databene.platform.csv.CSVEntityExporter">
<property name="uri" value="p2.csv"/>
<property name="encoding" value="UTF-8"/>
<property name="columns" value="ean_code,nom, prix"/>
</consumer>VI-A-3-c-iii. Fichier plat▲
<consumer class="org.databene.platform.flat.FlatFileEntityExporter">
<property name="uri" value="transactions.flat"/>
<property name="columns" value="id[8r0],ean_code[13],prix[8r0],items[4r0],date[8]"/>
<property name="datePattern" value="yyyyMMdd"/>
</consumer>VI-A-3-c-iv. La console▲
<consumer class="org.databene.model.consumer.ConsoleExporter"/>VI-A-3-c-v. Base de données▲
Paramétrer la base de données dans un premier temps.
<database id="db" url="jdbc:hsqldb:hsql" driver="org.hsqldb.jdbcDriver" user="sa" password="" schema="public"/>Puis
<generate name="Individu" count="500" consumer="db">VII. Exemples d'utilisation▲
VII-A. Anonymiser des données de production▲
Anonymiser des données de production est assez simple et se déroule en deux étapes :
- copie des données ;
- remplacement des champs qui doivent rester secrets.
L'étape 1 se réalise en configurant le paramètre « source » pour qu'il pointe sur la base de données de production.
L'étape 2 se réalise en remplaçant la valeur de production des champs par une autre valeur à l'aide de la balise <attribute>.
Par exemple :
<iterate type="Client" source="prod_db" consumer="test_db">
<attribute name="code_secret" value="secret" />
</iterate>Bien sûr il est possible d'utiliser toutes les possibilités (generator, validator, converter…).
Par exemple en utilisant le domain « Person ».
<iterate type="Client" source="prod" consumer="target" >
<variable name="Individu" generator="PersonGenerator"/>
<attribute name="Prenom" script="Individu.givenName" />
<attribute name="Nom" script="Individu.familyName" />
<attribute name="code_secret" value="secret" />
</iterate>Un exemple complet se trouve sur http://databene.org/databene-benerator/tutorials/123-production-data-anonymization-tutorial.html
VII-B. Créer un jeu de test pour l'application YAPS▲
Regardons comment créer un jeu de test pour un test de charge à partir de rien.
Nous allons nous inspirer du schéma de la base de données de l'application YAPS fourni avec le livre « Java EE 5 » d'Antonio Goncalves.
- Dans un premier temps, nous allons créer un fichier xml nommé shop.xml et tout de suite après nous allons le remplir avec :
<?xml version="1.0" encoding="iso-8859-1"?>
<setup xmlns="http://databene.org/benerator/0.6.3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://databene.org/benerator/0.6.3 http://databene.org/benerator-0.6.3.xsd">
</setup>- En regardant le schéma, on remarque qu'on aura besoin des domains « person », « net », « address » et « finance ». Afin de les utiliser, nous devons les importer.
<import defaults = "true"
domains = "person,net,address,finance"
platforms = "db"/>- Maintenant, définissons l'URL de la base de données (on utilisera PostgreSQL).
<database id="db" url="jdbc:postgresql://localhost:5432/postgres" driver="org.postgresql.Driver" user="sa" password="" schema="public"/>- Pour ne pas avoir de mauvaises surprises, partons d'une base vide (drop + create) à l'aide de 2 scripts SQL.
<execute uri="drop_tables.sql" target="db" onError="ignore"/>
<execute uri="create_tables.sql" target="db" optimize="true"/>
N'ayant pas le fichier SQL de création du schéma de base de données, nous partirons sur cette base.
DROP SEQUENCE seq_developpez_com_id_gen;
DROP TABLE T_ORDER_ORDER_LINE;
DROP TABLE T_ORDER_LINE;
DROP TABLE T_ITEM;
DROP TABLE T_PRODUCT;
DROP TABLE T_ORDER;
DROP TABLE T_CUSTOMER;
DROP TABLE T_ADDRESS;
DROP TABLE T_CATEGORY;CREATE SEQUENCE seq_developpez_com_id_gen;
CREATE TABLE T_CATEGORY (
id int NOT NULL,
name varchar(64),
description varchar(256),
PRIMARY KEY (id)
);
CREATE TABLE T_PRODUCT (
id int NOT NULL,
category_fk int NOT NULL,
name varchar(64),
description varchar(256),
PRIMARY KEY (id),
CONSTRAINT t_product_category_fk FOREIGN KEY (category_fk) REFERENCES T_CATEGORY (id)
);
CREATE TABLE T_ITEM (
id int NOT NULL,
product_fk int NOT NULL,
name varchar(64),
unit_cost int,
image_path varchar(256),
PRIMARY KEY (id),
CONSTRAINT t_item_category_fk FOREIGN KEY (product_fk) REFERENCES T_PRODUCT (id)
);
CREATE TABLE T_ADDRESS (
id int NOT NULL,
street1 varchar(128),
street2 varchar(128),
city varchar(128),
state varchar(128),
zip_code varchar(128),
country varchar(128),
PRIMARY KEY (id)
);
CREATE TABLE T_CUSTOMER (
id int NOT NULL,
address_fk int NOT NULL,
login varchar(64),
password varchar(64),
firstname varchar(64),
lastname varchar(64),
telephone varchar(64),
email varchar(64),
date_of_birth date,
PRIMARY KEY (id),
CONSTRAINT t_customer_address_fk FOREIGN KEY (address_fk) REFERENCES T_ADDRESS (id)
);
CREATE TABLE T_ORDER (
id int NOT NULL,
address_fk int NOT NULL,
customer_fk int NOT NULL,
order_date date,
credit_card_type varchar(64),
credit_card_number varchar(64),
credit_card_expiry_date date,
PRIMARY KEY (id),
CONSTRAINT t_order_address_fk FOREIGN KEY (address_fk) REFERENCES T_ADDRESS (id),
CONSTRAINT t_order_customer_fk FOREIGN KEY (customer_fk) REFERENCES T_CUSTOMER (id)
);
CREATE TABLE T_ORDER_LINE (
id int NOT NULL,
item_fk int NOT NULL,
quantity int,
PRIMARY KEY (id),
CONSTRAINT t_order_item_fk FOREIGN KEY (item_fk) REFERENCES T_ITEM (id)
);
CREATE TABLE T_ORDER_ORDER_LINE (
order_line_fk int NOT NULL,
order_fk int NOT NULL,
PRIMARY KEY (order_line_fk,order_fk),
CONSTRAINT t_order_order_line_fk FOREIGN KEY (order_line_fk) REFERENCES T_ORDER_LINE (id),
CONSTRAINT t_order_order_fk FOREIGN KEY (order_fk) REFERENCES T_ORDER (id)
);
À ce stade, nous avons une base de données vide et prête à recevoir nos données.
- Pour le remplissage des tables T_CATEGORY, T_PRODUCT et T_ITEM, nous allons importer des fichiers CSV. Cette solution a le mérite d'être facilement maintenable (avec Excel par exemple).
<iterate source="category.import.csv" type="T_CATEGORY" encoding="utf-8" consumer="db" />
<iterate source="product.import.csv" type="T_PRODUCT" encoding="utf-8" consumer="db" />
<iterate source="item.import.csv" type="T_ITEM" encoding="utf-8" consumer="db" />Les fichiers CSV seront :
"id","name","description"
1,"Fish","Any of numerous cold-blooded aquatic vertebrates characteristically having fins, gills, and a streamlined body"
2,"Dogs","A domesticated carnivorous mammal related to the foxes and wolves and raised in a wide variety of breeds"
3,"Reptiles","Any of various cold-blooded, usually egg-laying vertebrates, such as a snake, lizard, crocodile, turtle"
4,"Cats","Small carnivorous mammal domesticated since early times as a catcher of rats and mice and as a pet and existing
in several distinctive breeds and varieties"
5,"Birds","Any of the class Aves of warm-blooded, egg-laying, feathered vertebrates with forelimbs modified to form wings""id","name","description","category_fk"
1,"Angelfish","Saltwater fish from Australia",1
2,"Tiger Shark","Saltwater fish from Australia",1
3,"Koi","Freshwater fish from Japan",1
4,"Goldfish","Freshwater fish from China",1
5,"Bulldog","Friendly dog from England",2
6,"Poodle","Cute dog from France",2
7,"Dalmation","Great dog for a fire station",2
8,"Golden Retriever","Great family dog",2
9,"Labrador Retriever","Great hunting dog",2
10,"Chihuahua","Great companion dog",2
11,"Rattlesnake","Doubles as a watch dog",3
12,"Iguana","Friendly green friend",3
13,"Manx","Great for reducing mouse populations",4
14,"Persian","Friendly house cat, doubles as a princess",4
15,"Amazon Parrot","Great companion for up to 75 years",5
16,"Finch","Great stress reliever",5"id","name","unit_cost","image_path","product_fk"
1,"Large",10,"fish1.jpg",1
2,"Thootless",10,"fish1.jpg",1
3,"Spotted",12,"fish4.jpg",2
4,"Spotless",12,"fish4.jpg",2
5,"Male Adult",12,"fish3.jpg",3
6,"Female Adult",12,"fish3.jpg",3
7,"Male Puppy",12,"fish2.jpg",4
8,"Female Puppy",12,"fish2.jpg",4
9,"Spotted Male Puppy",22,"dog1.jpg",5
10,"Spotted Female Puppy",22,"dog1.jpg",5
11,"Spotted Male Puppy",32,"dog2.jpg",6
12,"Spotted Female Puppy",32,"dog2.jpg",6
13,"Tailed",62,"dog3.jpg",7
14,"Tailless",62,"dog3.jpg",7
15,"Tailed",82,"dog4.jpg",8
16,"Tailless",82,"dog4.jpg",8
17,"Tailed",100,"dog5.jpg",9
18,"Tailless",100,"dog5.jpg",9
19,"Female Adult",100,"dog6.jpg",10
20,"Female Adult",100,"dog6.jpg",10
21,"Female Adult",20,"reptile1.jpg",11
22,"Male Adult",20,"reptile1.jpg",11
23,"Female Adult",150,"lizard1.jpg",12
24,"Male Adult",160,"lizard1.jpg",12
25,"Male Adult",120,"cat1.jpg",13
26,"Female Adult",120,"cat1.jpg",13
27,"Male Adult",70,"cat2.jpg",14
28,"Female Adult",90,"cat2.jpg",14
29,"Male Adult",120,"bird2.jpg",15
30,"Female Adult",120,"bird2.jpg",15
31,"Male Adult",75,"bird1.jpg",16
32,"Female Adult",80,"bird1.jpg",16- Nous allons maintenant créer des clients (T_CUSTOMER) et leurs adresses (T_ADDRESS)
<generate type="T_ADDRESS" count="1000" consumer="db">
<variable name="adresse" generator="org.databene.domain.address.AddressGenerator" />
<id name="id" generator="idGen" />
<attribute name="street1" script="adresse.street" />
<attribute name="city" script="adresse.city" />
<attribute name="state" script="adresse.state" />
<attribute name="zip_code" script="adresse.postalCode" />
<attribute name="country" script="adresse.country" />
</generate>
<generate type="T_CUSTOMER" count="1000" consumer="db">
<variable name="individu" generator="org.databene.domain.person.PersonGenerator" dataset="FR" locale="fr"/>
<variable name="adresse" generator="org.databene.domain.address.AddressGenerator" />
<id name="id" generator="idGen" />
<attribute name="login" script="individu.givenName" />
<attribute name="password" pattern="[A-Za-z0-9]{8,12}" />
<attribute name="firstname" script="individu.givenName" />
<attribute name="lastname" script="individu.familyName" />
<attribute name="telephone" script="adresse.mobilePhone" />
<attribute name="email" script="individu.email" />
<attribute name="date_of_birth" script="individu.birthDate" />
<attribute name="address_fk" source="db" selector="select id from T_ADDRESS" cyclic="true" />
</generate>- Puis ces clients vont passer des commandes.
<generate type="T_ORDER" count="1000" consumer="db">
<id name="id" generator="idGen" />
<attribute name="order_date" min="2009-01-01" max="2010-04-01" />
<attribute name="credit_card_type" pattern="(Visa|Master Card|American Express)" />
<attribute name="credit_card_number" generator="org.databene.domain.finance.CreditCardNumberGenerator" />
<attribute name="credit_card_expiry_date" min="2010-04-01" max="2020-01-01" />
<attribute name="address_fk" source="db" selector="select address_fk from T_CUSTOMER" cyclic="true" />
<attribute name="customer_fk" source="db" selector="select id from T_CUSTOMER" cyclic="true" />
</generate>
<generate type="T_ORDER_LINE" count="1000" consumer="db">
<id name="id" generator="idGen" />
<attribute name="quantity" min="1" max="10" />
<attribute name="item_fk" source="db" selector="select id from T_ITEM" cyclic="true" />
</generate>
<generate type="T_ORDER_ORDER_LINE" count="1000" consumer="db">
<attribute name="order_line_fk" source="db" selector="select id from T_ORDER_LINE" cyclic="true" />
<attribute name="order_fk" source="db" selector="select id from T_ORDER" cyclic="true" />
</generate>- Il ne reste plus qu'à exécuter Benerator.

- Et voilà le résultat.
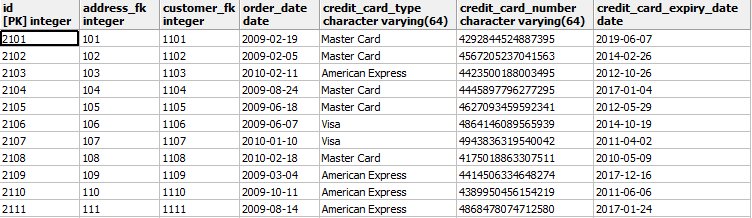

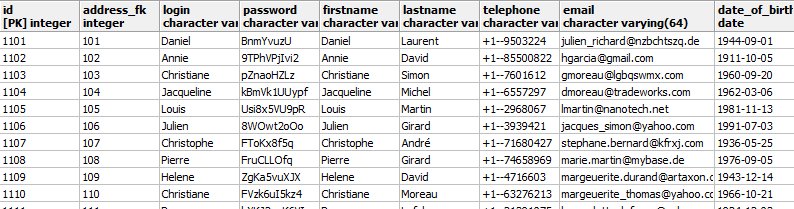
VII-C. Créer un jeu de test pour l'application Spring PetClinic▲
Nous allons créer un jeu de données pour l'application Spring PetClinic. En regardant d'un peu plus près, nous remarquons que dans sa configuration par défaut Petclinic utilise hsqldb. Pour initialiser son jeu de données, il utilise deux fichiers initDB.txt et populateDB.txt se trouvant dans le répertoire petclinic\WEB-INF\classes\db\hsqldb.
Ce que nous allons faire est simplement de générer un fichier populateDB.txt avec les données souhaitées.
Pour créer la structure de la base de données, on va utiliser le fichier initDB.txt.
On va mettre le maximum de données dans des fichiers csv.
Créons le fichier specialties.import.csv
"id","name"
1,"radiology"
2,"surgery"
3,"dentistry"Puis le fichier types.import.csv
"id","name"
1,"Angelfish"
2,"Tiger Shark"
3,"Koi"
4,"Goldfish"
5,"Bulldog"
6,"Poodle"
7,"Dalmation"
8,"Golden Retriever"
9,"Labrador Retriever"
10,"Chihuahua"
11,"Rattlesnake"
12,"Iguana"
13,"Manx"
14,"Persian"
15,"Amazon Parrot"
16,"Finch"
17,"cat"
18,"dog"
19,"lizard"
20,"snake"
21,"bird"
22,"hamster"Maintenant, nous allons créer le fichier SpringPetClinic.xml
En regardant le schéma, on remarque qu'on aura besoin des domains « person » et « address ». Afin de les utiliser, nous devons les importer.
<import defaults = "true"
domains = "person,address"
platforms = "db"/>Nous allons définir le fichier populateDB.txt comme fichier de sortie.
<bean id="fichier_sql" class="SQLEntityExporter">
<property name="uri" value="populateDB.txt"/>
<property name="dialect" value="hsql"/>
</bean>Afin de contourner le fait que Benerator ne sait pas gérer les clés étrangères lorsqu'on ne génère qu'un fichier texte en sortie, nous allons définir une base de données pour résoudre ces jointures.
<database id="db" url="jdbc:hsqldb:hsql" driver="org.hsqldb.jdbcDriver" user="sa" />Et on mettra deux consumers pour chaque entité générée.
consumer="fichier_sql,db"Pour le reste, on le traitera comme pour l'exemple précédent. Ce qui nous donnera un fichier SpringPetClinic.xml de la forme suivante.
<?xml version="1.0" encoding="iso-8859-1"?>
<setup xmlns="http://databene.org/benerator/0.6.3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://databene.org/benerator/0.6.3 http://databene.org/benerator-0.6.3.xsd">
<import defaults = "true"
domains = "person,address"
platforms = "db"/>
<bean id="fichier_sql" class="SQLEntityExporter">
<property name="uri" value="populateDB.txt"/>
<property name="dialect" value="hsql"/>
</bean>
<database id="db" url="jdbc:hsqldb:hsql" driver="org.hsqldb.jdbcDriver" user="sa" />
<bean id="idGen" spec="new IncrementGenerator(1)" />
<execute uri="initDB.txt" target="db" onError="ignore"/>
<iterate source="specialties.import.csv" type="specialties" encoding="utf-8" consumer="fichier_sql,db" >
<id name="id" type="long" />
<attribute name="name" type="string" script="specialties.name" />
</iterate>
<iterate source="types.import.csv" type="types" encoding="utf-8" consumer="fichier_sql,db" >
<id name="id" type="long" />
<attribute name="name" type="string" script="types.name" />
</iterate>
<generate type="vets" count="50" consumer="fichier_sql,db">
<variable name="individu" generator="org.databene.domain.person.PersonGenerator" dataset="FR" locale="fr"/>
<id name="id" generator="idGen" type="long" />
<attribute name="first_name" script="individu.givenName" />
<attribute name="last_name" script="individu.familyName" />
</generate>
<generate type="owners" count="50" consumer="fichier_sql,db">
<variable name="individu" generator="org.databene.domain.person.PersonGenerator" dataset="FR" locale="fr"/>
<variable name="adresse" generator="org.databene.domain.address.AddressGenerator" />
<id name="id" generator="idGen" type="long" />
<attribute name="first_name" script="individu.givenName" />
<attribute name="last_name" script="individu.familyName" />
<attribute name="address" script="adresse.houseNumber + ' ' + adresse.street" />
<attribute name="city" script="adresse.city" />
<attribute name="telephone" script="adresse.mobilePhone" />
</generate>
<generate type="vet_specialties" count="50" consumer="fichier_sql,db">
<reference name="vet_id" targetType="vets" source="db" distribution="random" />
<reference name="specialty_id" targetType="specialties" source="db" distribution="random" />
</generate>
<generate type="pets" count="50" consumer="fichier_sql,db">
<variable name="individu" generator="org.databene.domain.person.PersonGenerator" dataset="US" locale="US"/>
<id name="id" generator="idGen" type="long" />
<attribute name="name" script="individu.givenName" />
<attribute name="birth_date" min="2009-01-01" max="2010-04-01" type="date" />
<attribute name="type_id" source="db" selector="select id from types" cyclic="true" />
<attribute name="owner_id" source="db" selector="select id from owners" cyclic="true" />
</generate>
<generate type="visits" count="50" consumer="fichier_sql,db">
<id name="id" generator="idGen" type="long" />
<attribute name="pet_id" source="db" selector="select id from pets" cyclic="true" />
<attribute name="visit_date" min="2009-01-01" max="2010-04-01" type="date" />
<attribute name="description" pattern="(rabies shot|neutered|spayed)" />
</generate>
</setup>VIII. Conclusion▲
Comme on a pu le voir Benerator remplit parfaitement sa tâche grâce à sa richesse fonctionnelle et son adaptabilité. Et ces deux points peuvent encore être améliorés en faisant du développement Java par dessus Benerator. De plus on peut générer différents volumes de données pour tous les environnements (développement, pré production…) assez facilement à l'aide de fichiers properties. La contrepartie à ces qualités est que l'écriture du fichier de configuration de Benerator demande un certain temps.
On trouvera beaucoup plus d'informations sur le site de Benerator.
IX. Remerciements▲
Merci à Volker Bergmann pour son aide sur Benerator.
Merci à Antonio Goncalves pour l'autorisation de l'utilisation de l'application YAPS.
Merci à blade159 pour sa relecture orthographique.
Merci à Caro-Line pour sa relecture orthographique.
Merci à Mahefasoa pour sa relecture orthographique.
X. Références▲
Site du produit : http://databene.org/