




I. Introduction▲
Malgré l'augmentation de la puissance des machines, il arrive que les objectifs de performance d'une application J2EE ne soient pas atteints. Pour cela il faut mettre en place une politique d'analyse de performance.
Cette politique doit être considérée à toutes les étapes du projet (et le plus tôt possible) et par tous les acteurs du projet.
L'architecte doit faire une architecture évolutive, le développeur doit créer le code le plus propre possible afin que l'optimiseur soit le plus pertinent, ce code doit bien sûr être testé…
Mais il faut faire attention à ne pas vouloir tout optimiser et se concentrer seulement sur le code source. Une bonne devise serait « Ne devinez pas, mesurez ».
Nous allons voir dans cet article comment mesurer les performances et corriger les problèmes trouvés.
Pour cela nous définirons une démarche que nous outillerons.
Dans cette démarche nous apprendrons à :
- faire un test de charge afin d'observer les comportements (consommation de ressources, temps de réponse…) de l'application et son évolution en fonction de différents paramètres (nombre d'utilisateurs simultanés, temps de pause entre chaque action (thinktime)…) ;
- mettre en place un profileur sur le code afin de cerner de manière précise les problèmes ;
- analyser les résultats ;
- corriger ces problèmes.
Comme vous le verrez, la mesure des performances et la correction demandent de vastes connaissances et donc il est utile de collaborer avec des spécialistes, en particulier les administrateurs de serveurs d'applications et les administrateurs de bases de données (DBA).
Dernière chose importante, il faut se méfier des « Performance Tips » qui dépendent du contexte d'utilisation, par exemple une solution peut fonctionner dans un cas et s'avérer catastrophique dans une autre situation ou avec les versions suivantes des composants utilisés (JVM, base de données…).
II. Procédure de test▲
On va utiliser la méthode suivante :
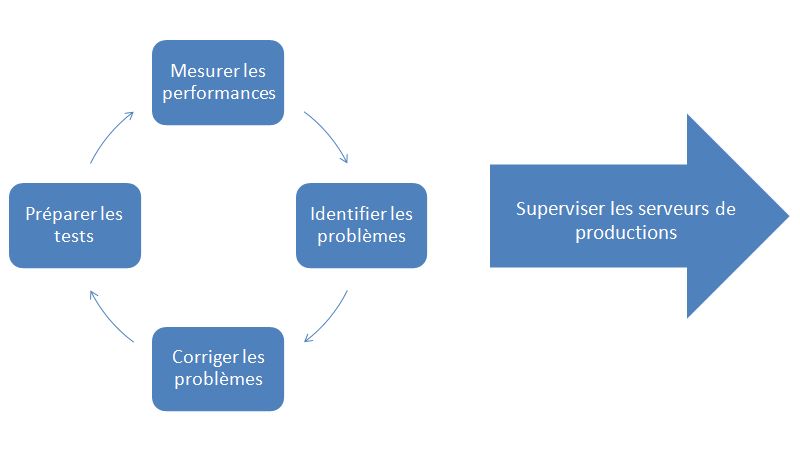
II-A. Préparation des tests▲
La définition des objectifs est une étape importante et doit faire intervenir un certain nombre de personnes du projet.
Plus d'informations sur mon article « Créer des plans de tests de charge réalistes ».
II-A-1. Définition du type de test▲
La première chose à définir est le type de test que l'on veut faire.
Plus d'informations ici.
II-A-2. Définition des objectifs de performance▲
Plus d'informations ici.
II-A-3. Préparation de la machine cible▲
Plus d'informations ici.
II-A-4. Choix des scénarios▲
Plus d'informations ici.
II-A-5. Choix des outils▲
Il est important de choisir des outils que l'on maîtrise.
Plus d'informations ici.
II-A-6. Mesure des performances▲
Dans cette partie, on utilisera des outils de test de charge (HP LoadRunner, Apache Jmeter…) pour simuler l'application. Jmeter sera utilisé pour la suite.
Il peut être judicieux d'utiliser des outils de supervision métiers de la performance (Introscope, Dynatrace …).
II-A-7. Identifier les problèmes▲
Encore une fois, un certain nombre d'outils existent.
Cela va des outils intégrés à la JDK à des outils coûtant très cher en passant par les outils intégrés aux IDE (Netbeans, Eclipse…).
Voilà les catégories des outils que nous utiliserons.
II-A-7-a. Memory debugger▲
Cela nous permettra de :
- trouver les fuites de mémoire ;
- réduire la consommation de la mémoire ;
- identifier rapidement les méthodes qui créent les objets.
Par exemple avec Yourkit Java Profiler.
II-A-7-b. Profiler▲
Cela nous permettra de :
- découvrir les goulots d'étranglement ;
- avoir des mesures par ligne d'instruction.
Par exemple avec Yourkit Java Profiler.
II-A-7-c. Thread analyseur▲
Cela nous permettra de :
- détecter les verrous mortels (dead lock) ;
- détecter les Conditions de course (Race conditions).
Par exemple avec Yourkit Java Profiler.
II-A-7-d. Serveur d'application monitoring▲
Avec le serveur d'application, souvent il y a un module de monitoring.
Cela nous permettra de :
- détecter si la taille des pools est correcte.
II-A-7-e. Base de données monitoring▲
La plupart des bases de données ont un outil de monitoring. Par exemple, Oracle dispose de DB Console.
Cela nous permettra de :
- détecter les requêtes les plus lentes ;
- détecter les requêtes les plus utilisées ;
- tuner les paramètres du serveur de base de données.
II-A-8. Corriger les problèmes▲
Comme on le verra dans la suite, les corrections peuvent intervenir à plusieurs endroits (configuration de la base de données, configuration de la JVM, au niveau source… ) et pourront faire intervenir différentes personnes (DBA, développeur, administrateur…). Une fois la correction faite, relancer les tests (on voit bien l'avantage d'avoir des tests automatisés dans ce cas) jusqu'à atteindre les objectifs.
II-A-9. Superviser les serveurs de productions▲
Le test de performance/charge n'est qu'une simulation plus ou moins réaliste et donc il est important de mettre sous surveillance les serveurs de productions.
II-B. Mesure des performances▲
II-B-1. Test de charge▲
Pour le test de charge nous allons utiliser JMeter qui sera présenté de manière sommaire, mais suffisante pour notre exemple.
Vous trouverez plus d'informations sur http://blog.milamberspace.net/index.php/jmeter-pages
II-B-1-a. Présentation de JMeter▲
Plus d'informations ici
II-B-1-b. Construction d'un plan de tests▲
Comme indiqué plus haut, à cette étape il faut choisir avec les utilisateurs et/ou le chef de projet et/ou l'AMOA un certain nombre de scénarios et le nombre d'utilisateurs associés.
Par exemple, supposons que l'application doive tenir la charge de 100 utilisateurs simultanés et que :
- 90 % des utilisateurs feront de la consultation ;
- 9 % des utilisateurs feront de la modification ;
- 1 % des utilisateurs feront de l'administration.
Dans ce cas un plan de test possible sera :
|
Scénario |
descriptif |
nombre d'utilisateurs |
|---|---|---|
|
Consultation |
Se connecter avec les droits Consultation |
90 |
|
Modification |
Se connecter avec les droits Modification |
9 |
|
Administration |
Se connecter avec les droits Administration |
1 |
II-B-1-c. Développer un plan de test▲
II-B-1-d. Exécuter les tests▲
Plus d'informations ici.
II-B-1-e. Analyse des premiers résultats▲
Pendant les tests de charge, afin de paramétrer l'application pour bien répartir les traitements et avoir le maximum d'utilisateurs en simultanée, il est souhaitable de bien configurer chaque pool (connexion, thread) de chaque serveur afin de diminuer les temps d'attente entre eux.
Prenons une application n tiers classique
Sur chaque partie il faut surveiller :
-
Serveur web :
- taux d'occupation du pool de thread ;
- nombre de thread en attente ;
- taux d'occupation du processeur.
-
Serveur d'application :
- taux d'occupation du pool de thread ;
- nombre de thread en attente ;
- taux d'occupation du processeur.
-
Serveur de bases de données :
- taux d'occupation du pool de connexion ;
- nombre de connexions en attente ;
- taux d'occupation du processeur.
Le principe est de paramétrer le nombre de connexions/thread sur chaque serveur afin :
- d'avoir un taux d'occupation processeur inférieur à 80 % ;
- d'avoir un minimum de thread/connexions en attente ;
- d'avoir un taux d'occupation des pools le plus haut possible.
Pour cela il faut bien avoir en tête que si un des tiers est surdimensionné par rapport au suivant, il va lui « donner trop de travail à faire ».
Par exemple si le serveur d'application est capable de traiter beaucoup de demandes, il va demander au serveur de bases de données trop de requêtes et donc devra attendre qu'il les traite. Or avec cette surcharge de travail, le serveur de bases de données va traiter de moins en moins rapidement les demandes.(Dans ce cas, c'est donc la base de données qui sera le goulot d'étranglement de l'architecture.)
L'utilisation d'outils système (vmstat, mpstat, iostat, DTrace, Gestionnaire des tâches…) ou d'outils de monitoring pour surveiller un certain nombre de paramètres est une bonne idée.
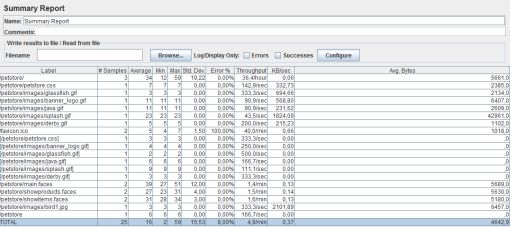
Pour avoir les temps de réponse des requêtes/transactions échangés entre l'application et JMeter, les items listeners de JMeter le font très bien.
Par exemple avec Summary Report, on a les mesures intéressantes pour les temps de réponse :
- Average (ms) : moyenne des temps de réponse ;
- Min (ms) : valeur du plus petit temps de réponse ;
- Max (ms) : valeur du plus grand temps de réponse ;
- Std. Dev. : l'écart-type.
Si les tests de charge sont concluants et que le taux d'occupation des serveurs est bon, le test peut s'arrêter.
II-C. Identifier et corriger les problèmes▲
Si les tests de charge n'ont pas été concluants, il va falloir chercher d'où vient le problème. Pour cela il existe un certain nombre d'outils.
Les problèmes possibles sont ici regroupés avec une solution possible et comment le détecter.
II-C-1. Consommation CPU▲
Avec le test de charge, on a pu avoir des temps de réponse de manière globale, il est temps de regarder de manière plus précise.
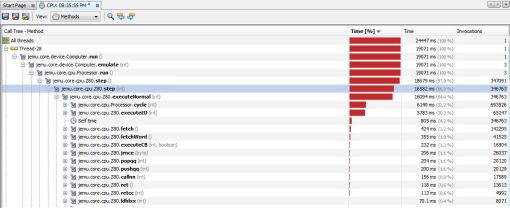
À l'aide du profiler, on va pouvoir calculer pour chaque package/class/méthode/… du programme :
- le temps d'exécution ;
- le nombre d'utilisations.
Il faudra chercher à optimiser les parties :
- ayant le plus grand temps d'exécution et utiliser un certain nombre de fois ;
- utilisées de nombreuses fois.
Il faut faire attention, un temps d'exécution d'une méthode peut être long, car il est en attente de quelque chose (par exemple le résultat d'une requête SQL) et dans ce cas-là, la partie à optimiser est la requête SQL et non la méthode en elle-même.
Avant de passer à l'optimisation, vérifier que les algorithmes utilisés sont performants, car il n'y aura pas de miracle s'il y a eu un mauvais choix de ce côté. De même, si le taux d'occupation processeur est supérieur à 80 %, il faut adapter chaque partie de l'architecture afin de descendre en dessous de 80 %. Si cela n'est pas possible, il faut envisager d'augmenter les capacités hardware des serveurs.
Pour augmenter les capacités hardware, on peut :
- ajouter de la mémoire, mettre un disque dur plus rapide… ;
- multiplier les serveurs et faire du Load balancing.
II-C-2. Consommation mémoire▲
Si lors des tests de charge on détecte :
- consommation de mémoire trop importante ;
- consommation de mémoire qui ne fait qu'augmenter ;
- ou pire, un crash avec un OutOfMemory ;
- un comportement étrange du Garbage Collector (GC) ;
- une fréquence d'exécution du GC trop grande.
C'est qu'il faut regarder d'un peu plus près la gestion de la mémoire.
II-C-2-a. Comment marche la mémoire▲
Avant de commencer, il est important de savoir comment est gérée la mémoire par la JVM.
Attention, les JVM (en fonction de la version et de l'éditeur (SUN, IBM…)) ne marchent pas toutes pareilles.
Prenons par exemple la JVM 5 de SUN.
La mémoire est composée de deux zones :
- la Heap : cette zone mémoire permet d'allouer les objets courants. Les options Xmx et Xms permettent de faire varier sa taille ;
- la Permanent Generation (Permanent Space) : cette zone est réservée au chargement des classes. L'option XX:MaxPermSize permet de définir sa taille maximum.
La Heap est composée de deux zones :
- New Generation : c'est dans cette zone mémoire que sont alloués les nouveaux objets. Les options XX:MaxNewSize et XX:NewSize permettent de faire varier sa taille ;
- Old Generation : c'est ici que les objets avec une longue durée de vie se retrouvent à un moment.
La New Generation est composée de deux zones :
- Eden
-
Survivor. L'option XX:SurvivorRatio permet de définir sa taille.
- From
- To
En plus des zones mémoire, il y a le GC (garbage collector) qui supprime de la mémoire les objets non utilisés (objets qui ne sont plus rattachés à la GC root).
Il existe deux types de GC :
- Minor GC : qui s'exécute rapidement et fréquemment sur la zone New Generation ;
- Major/full GC : qui s'exécute plus lentement (tous les processus sont arrêtés…) et moins souvent et seulement sur la zone Old Generation.
Le principe de fonctionnement de la Heap est le suivant :
- lors de l'allocation d'un objet, il est placé dans la zone mémoire Eden ;
- lorsque la zone Eden est pleine, un minor GC est exécuté et les objets vivants sont copiés dans From ;
- lorsque la zone From est pleine, un minor GC est exécuté et les objets vivants sont copiés dans To ;
- lorsque la zone To est pleine, les objets sont copiés dans Old Generation ;
- lorsque la zone Old Generation est pleine, un major/full GC est exécuté.

De ces explications, on peut en conclure qu'il faut minimiser les major GC. Pour cela il est important de :
- préférer les objets avec une courte durée de vie afin d'éviter de passer dans la zone Old Generation ;
- ajuster la taille de la zone Young Generation. SUN préconise que la taille de la zone Young Generation soit inférieure à 50 % de la taille de la Heap ;
- la taille minimum de la Heap (option -Xms) doit être suffisante pour éviter qu'elle ne croisse (car pour croître il faut un major GC) ;
- la taille maximale de la Heap (option -Xmx) doit être supérieure à sa taille minimale pour éviter les crashes ou égale pour plus de performance.
On peut aussi paramétrer le fonctionnement de la GC. Par exemple le paramètre -XX:+UseParallelGC pour les serveurs multi processeur (normalement c'est automatique pour ce type de machine)
Il y a de nombreux outils qui nous permettent de surveiller l'activité du GC (VisualVM, VisualGC…).
On pourra vérifier :
- l'utilisation de la Heap : taille utilisée, taille maximale… ;
- la fréquence de l'activité du GC ;
- le temps de l'exécution de la GC ;
- le type de GC exécuté.
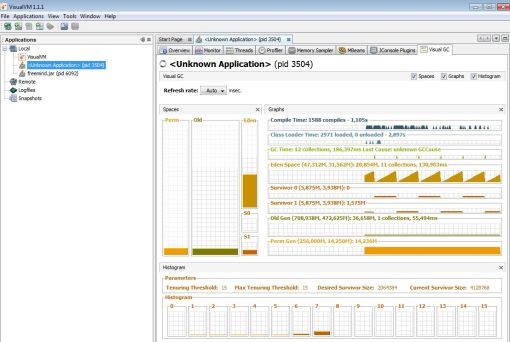
Afin d'avoir des informations sur le GC, ajouter -verbose:gc, -XX:+PrintGCTimeStamps, -XX:+PrintGCDetails aux paramètres de la JVM
Pour avoir plus d'information sur la gestion de la mémoire par la JVM
https://gfx.developpez.com/tutoriel/java/gc/
Pour les options de la JVM
http://blogs.sun.com/watt/resource/jvm-options-list.html
Pour des conseils de tuning
http://java.sun.com/javase/technologies/hotspot/gc/gc_tuning_6.html
II-C-2-b. Fuite de mémoire▲
Comme on l'a vu sur la partie fonctionnement de la mémoire, les objets de la fuite de mémoire ont de fortes chances de se trouver dans la zone mémoire Old Generation et donc afin de gagner du temps, on peut se concentrer sur cette partie.
Les deux problèmes majeurs viennent de la mauvaise utilisation :
- des objets en HTTP session ;
- des collections.
Il existe de nombreuses méthodes permettant de trouver une fuite mémoire. Mais avant de commencer, il est important de savoir qu'un OutOfMemoryError ne vient pas forcément d'une fuite de mémoire. Donc la première chose à faire est de bien paramétrer la configuration mémoire de la JVM.
II-C-2-b-i. Analyse de fuite de mémoire à partir de dump▲
Un dump est une copie de tout ce qu'il y a en mémoire de la JVM. De cette manière on peut savoir le nombre d'objets vivants, leurs consommations mémoire…
- On crée le dump.
Il existe plusieurs moyens.
En paramétrant la JVM avec les options :
-
-XX:+HeapDumpOnOutOfMemoryError
- Un fichier dump est créé lors d'un OutOfMemoryError.
-
-XX:+HeapDumpOnCtrlBreak
- Un fichier dump est créé lors d'un appui sur CTRL+BREAK sous Windows ou un kill -3 pid sous Unix.
Avec des outils :
-
Sun JMap
- jmap.exe -dump:format=b,file=HeapDump.hprof pid (pid est obtenu avec jps).
-
Sun JConsole
- Commande dumpHeap.
-
Outils SAP JVMMon/MMC
- Dans le menu il y a « Dump Stack Trace ».
- VisualVM ;
- Netbeans ;
- …
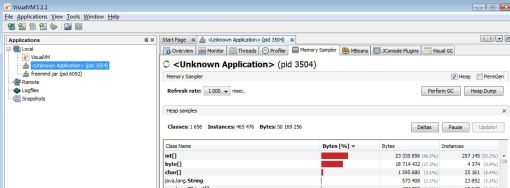
- On traite le dump.
En fonction de l'éditeur de la JVM, on pourra ouvrir le dump avec un certain nombre d'outils comme :
- JHAT ;
- NetBeans Profiler ;
- VisualVM ;
- SAP Memory Analyzer ;
- …
- On analyse le dump.
Là encore, de nombreuses méthodes peuvent être utilisées.
Par exemple on peut comparer deux dumps (avant lancement du traitement et après le traitement) afin de visualiser les objets qui restent en mémoire après traitement.
Un autre point de départ est de repérer les objets qui consomment énormément de mémoire.
Une fois les objets choisis (quel que soit le point de départ), le principe est d'aller dans les détails jusqu'à trouver la fuite mémoire dans le code.
II-C-2-c. Utilisation des chaînes de caractères▲
La mauvaise gestion des chaînes de caractères en Java peut engendrer une « surcréation » d'objets et une surconsommation de mémoire.
Par exemple :
- pour concaténer les chaînes de caractères, utiliser la classe StringBuffer/StringBuilder ;
- préférer String s = « MaChaineDeCaracteres » à String s = new String(« MaChaineDeCaracteres ») ;
- créer les chaînes de caractères avec la bonne taille (Findbugs peut vous y aider) ;
- …
Attention, car avec le compilateur JIT (Just In Time), cela n'est pas toujours nécessaire.
On peut détecter une mauvaise utilisation des chaînes de caractères de la manière suivante.
Pour cela on va partir de ce code :
package teststring;
public class Main {
public static void main(String[] args) {
String s = "MaChaineDeCaractere";
for (int i = 0; i < 100000; i++) {
s = s + "Ajout";
}
}
}Puis profilons ce code.
Regardons d'un peu plus près la mémoire
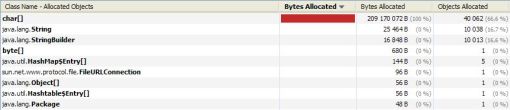
On remarque qu'il y a beaucoup d'allocations de char[] ou de String.
Et donc que ce projet est un bon candidat pour l'utilisation de StringBuffer.
Pour information, le temps d'exécution est de 1.73 s

Maintenant, changeons le String en StringBuffer
package teststring;
public class Main {
public static void main(String[] args) {
StringBuffer s = new StringBuffer("MaChaineDeCaractere");
for (int i = 0; i < 100000; i++) {
s.append("Ajout");
}
}
}On remarque que maintenant il y a beaucoup moins d'allocations de Char[] en mémoire

Le temps d'exécution passe à 0.0036 s

Puis changeons les StringBuffer en StringBuilder, car on n'a pas besoin d'être thread-safe
package teststring;
public class Main {
public static void main(String[] args) {
StringBuilder s = new StringBuilder("MaChaineDeCaractere");
for (int i = 0; i < 100000; i++) {
s.append("Ajout");
}
}
}Le nombre d'allocations de Char[] en mémoire reste identique, mais le temps d'exécution descend à 0.0034 s


Maintenant, initialisons le StringBuilder directement avec la bonne taille
package teststring;
public class Main {
public static void main(String[] args) {
StringBuilder s = new StringBuilder(50019);
s.append("MaChaineDeCaractere");
for (int i = 0; i < 100000; i++) {
s.append("Ajout");
}
}
}Le nombre d'allocations de Char[] diminue

Le temps d'exécution passe à 0.0034 s

Avec ces quelques conseils, on a réussi à diminuer :
- le temps d'exécution ;
- le nombre d'allocations de Char[] et donc les fréquences du fonctionnement du GC.
Et cela assez facilement en profilant la mémoire.
II-C-2-d. Trop d'objets▲
Comme vu précédemment, la création d'objets augmente la fréquence de déclenchement du GC. Et donc il faut éviter la création d'objets inutiles.
Par exemple :
- sortir si c'est possible la création d'objets des boucles ;
- utilisation de Integer.parseInt(s) à la place de Integer.valueOf(s).intValue() ;
- …
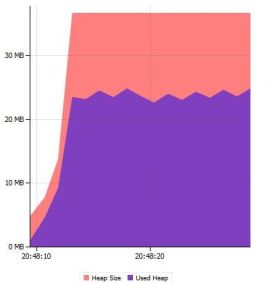
Il y a un certain nombre de règles dans FindBugs et PMD qui permettent de trouver ces points dans le code source de l'application.
Sinon il faut regarder le graphe du GC.
II-C-2-e. Frameworks de persistance : Hibernate▲
Les frameworks de persistance sont pratiques, mais il faut faire attention à leur utilisation, car il y a beaucoup de choses qui sont « cachées ».
Nous allons nous focaliser sur Hibernate.
La première chose à faire si on a des doutes sur Hibernate est d'activer les logs pour savoir exactement ce qu'il se passe.
Pour cela il faut mettre à true le paramètre hibernate.show_sql
Il est aussi possible d'activer les statistiques pour encore plus d'informations avec le paramètre hibernate.generate_statistics
Plus d'informations sur mon premier article sur Hibernate
Une fois cela fait, on va travailler sur deux parties, les clés primaires autoincrémentées et les stratégies de chargement. Et enfin on verra une manière de faire des recherches multicritères avec Hibernate.
Quelques conseils peuvent se trouver sur http://blog.octo.com/antipattern-hibernate/et http://www.javalobby.org/articles/hibernate-query-101/
N'hésitez pas à faire appel à un DBA si c'est possible.
II-C-2-e-i. Clés primaires autoincrémentées▲
Par défaut, Hibernate nécessite deux requêtes SQL pour insérer un objet dans une table avec une clé primaire auto incrémenté.
En effet, l'élément generator (qui est utilisé pour définir la stratégie utilisée pour générer les identifiants uniques) vaut identity ou sequence en fonction de la base de données. Or ce n'est pas la stratégie optimale et donc il peut être utile d'utiliser les valeurs hilo ou seqhilo afin d'optimiser le temps d'insertion.
Plus d'informations sur le site officiel.
II-C-2-e-ii. Les stratégies de chargement▲
Lors d'une requête SQL, Hibernate ne réagira pas de la même façon pour charger les résultats en fonction d'un certain nombre de paramètres.
C'est pourquoi il est important de bien définir la stratégie de chargement afin d'éviter le syndrome du N+1 selects (on exécute une requête de plus que nécessaire).
Les stratégies de chargement sont divisées en deux groupes qui sont le quand et le comment.
Pour le quand, il y a :
- chargement immédiat : Hibernate charge toutes les données nécessaires immédiatement ;
- chargement tardif : Hibernate charge les données seulement lorsque cela est nécessaire.
Il faut donc faire très attention si on bascule (par défaut on est en chargement tardif) sur le mode chargement immédiat afin de ne pas surcharger la mémoire.
Pour le comment, c'est la manière de gérer les associations et on a le choix entre :
- chargement par select : c'est celui par défaut et X Select seront exécutés lorsqu'on accède à l'association ;
- chargement par sous-select : le 1er Select récupère tous les paramètres de la clause Where du 2e Select ;
- chargement par jointure : un seul Select avec jointure est utilisé pour accéder à l'association ;
- chargement par lot : un seul Select est utilisé.
Pour résumer, il faut faire attention à la combinaison du quand et du comment. Mais une fois maîtrisé, c'est un bon moyen de diminuer le nombre de requêtes SQL en particulier lorsque l'objet Père contient une très grande collection d'enfants.
Plus d'informations sur le site officiel, sur https://bmarchesson.developpez.com/tutoriels/java/hibernate/chargement/ et sur mon tutoriel.
II-C-2-e-iii. Recherche multicritère▲
Lorsqu'on a une recherche multicritère à faire, il peut être judicieux d'utiliser l'API Criteria de Hibernate afin d'éviter la construction d'une requête HQL à la volée.
Plus d'informations sur https://java.developpez.com/faq/hibernate/?page=Criteria et http://www.javalobby.org/articles/hibernatequery102/
II-C-3. Optimisation de la partie base de données▲
Lors du développement d'une application, souvent les développeurs développent et recettent sur une volumétrie bien plus faible que celle de la production réelle. Les temps de réponse ainsi obtenus peuvent être raisonnables malgré des requêtes mal écrites et ce n'est que lors des tests de charge ou en production que les problèmes apparaissent.
C'est pour cela qu'il est important d'avoir un environnement de test avec le même jeu de données et l'aide d'un DBA si c'est possible.
Si les performances de l'application sont critiques, on peut sacrifier l'interportabilité en utilisant au maximum toutes les spécificités du serveur de bases de données utilisé.
Plus d'informations sur
http://wiki.postgresql.org/wiki/Performance_Optimization
et
https://sqlpro.developpez.com/cours/optimiser/
Voyons maintenant comment optimiser les performances.
II-C-3-a. Pool de connexion JDBC▲
Un pool de connexion permet de créer un certain nombre de connexions au démarrage du serveur d'application. Cela permet de ne pas créer de connexion (process qui est très gourmand) en cours de vie de l'application.
Si on se retrouve avec trop de connexions en attente, il peut être utile d'augmenter le pool de connexion JDBC du serveur d'application. Il faut faire attention au moins à deux choses afin de choisir le bon nombre :
- la charge processeur ne doit pas dépasser 80 % ;
- ce nombre dépend aussi du nombre de thread.
II-C-3-b. TableSpace▲
Un tablespace est l'espace de stockage où sont stockés les objets de la base de données.
Il faut bien définir les tablespace en les répartissant sur plusieurs disques durs si nécessaire. Par exemple il peut être judicieux de placer les objets (indexes, tables…) souvent utilisés dans un ou plusieurs tablespaces sur les disques durs les plus rapides.
Plus d'informations sur https://oracle.developpez.com/guide/architecture/tablespaces/
II-C-3-c. Génération des statistiques▲
Afin de déterminer le meilleur plan d'exécution d'une requête, les serveurs de base de données utilisent une série de statistiques. Cela signifie qu'en fonction de divers paramètres (volumétrie, répartition des données…) on aura un plan d'exécution différent et que ce plan d'exécution pourra évoluer avec le temps.
Donc il est important que ces statistiques soient à jour. Pour cela il existe des outils spécifiques à chaque base de données comme Runstats sous DB2, DBMS_STATS sous Oracle et VACUUM sous PostgreSQL.
Il peut être utile de récupérer les statistiques de la base de données en production et de les mettre sur la machine de test afin de pouvoir reproduire les problèmes.
II-C-3-d. Détecter les requêtes coûteuses▲
De nombreux outils permettent d'avoir un historique des requêtes exécutées par l'application.
Sous Oracle 10g il y a AWR (Automatic Workload Repository) et STATPACK.
Plus d'information sur STATPACK : https://oracle.developpez.com/guide/tuning/statpack/
Sous Oracle, on a aussi la vue système nommée v$sqlarea qui le permet.
Par exemple avec cette vue on pourra avoir les informations suivantes :
- Sql_FullText : l'ordre sql ;
- cpu_time : temps CPU ;
- elapsed_time : temps d'exécution ;
- fetches : nombre de lignes retournées ;
- buffer_gets : le nombre de block mémoire lus ;
- disk_reads : le nombre de block disque lus ;
- executions : le nombre d'exécutions ;
- rows_processed : le nombre de lignes traitées ;
Avec ces informations, on peut diagnostiquer un certain nombre de problèmes.
Pour MySQL, on peut lancer le serveur avec les options --log-slow-queries et --log-queries-not-using-indexes afin d'avoir les requêtes qui posent problème dans un fichier log.
II-C-3-d-i. Plan d'exécution d'une requête▲
Une fois les requêtes coûteuses détectées, on va essayer de savoir pourquoi elles le sont.
Pour cela on peut activer les traces (sous Oracle avec la commande SET AUTOTRACE ON) ou de faire un explain sur une requête.
Cela nous permettra d'avoir le plan d'exécution de la requête afin de savoir comment elle se comporte exactement.
Par exemple, on pourra savoir si elle utilise un index et son coût.
- Voilà un exemple de l'utilisation d'un EXPLAIN sous PostgreSQL.
select * from db_order join db_order_item on db_order.id=db_order_item.order_id
where customer_id= 4donne
"Hash Join (cost=6.81..39.65 rows=20 width=56) (actual time=0.231. 5.050 rows=16 loops=1)"
" Hash Cond: (db_order_item.order_id = db_order.id)"
" -> Seq Scan on db_order_item (cost=0.00..27.01 rows=1501 width=32) (actual time=0.023. 2.291 rows=1501 loops=1)"
" -> Hash (cost=6.76. 6.76 rows=4 width=24) (actual time=0.177. 0.177 rows=4 loops=1)"
" -> Seq Scan on db_order (cost=0.00. 6.76 rows=4 width=24) (actual time=0.081. 0.161 rows=4 loops=1)"
" Filter: (customer_id = 4)"
"Total runtime: 5.255 ms"Et de manière visuelle
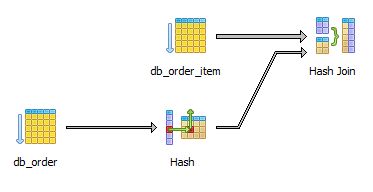
Afin de pouvoir étudier le résultat il faut savoir que :
Accès aux données des tables
Parcours séquentiel :
Full Table Scans
La table est directement lue à partir du disque dur et n'utilise ni le cache ni aucun index.
…
Parcours d'index :
Index Full Scan
L'index est directement lu à partir du disque dur et n'utilise pas le cache.
Fast Full Index Scan
La même chose que Index Full Scan, mais en plus rapide (la stratégie de lecture sur disque dur n'est pas la même).
…
ROWID Scan
Accès direct à un ensemble de tuples
Jointure
Nested Loops
Lorsque deux tables sont jointes par Nested Loops, il y en a donc une qui boucle sur une autre.
Hash Join
Une table de hachage est créée pour la jointure.
…
- Pour le SET AUTOTRACE ON
Recursives calls : une instruction SQL appelle d'autres requêtes SQL.
Consistents gets : lecture dans le cache de Oracle.
II-C-3-d-ii. Index▲
Avec le plan d'exécution d'une requête, on peut se rendre compte de deux choses.
La 1re chose est qu'il faut ajouter un index afin d'accélérer la requête
Avant d'ajouter un index, il est important de savoir qu'un index accélère les lectures, mais ralentit les écritures.
Les index seront créés en priorité lorsque :
- une ou plusieurs colonnes sont fréquemment utilisées dans une clause where ou dans une condition de jointure ;
- la table est de grande taille et que la plupart des requêtes ne ramènent qu'un nombre restreint de lignes.
Faire attention à ce que :
- l'index soit suffisamment discriminant ;
- l'ordre des colonnes composant un index composite soit le plus pertinent.
Une fois qu'on a choisi les colonnes composant l'index, il ne reste plus qu’à choisir le type d'index.
Par exemple un index de type B-tree par défaut et un index bitmap lorsqu'il porte sur une colonne avec très peu de valeurs distinctes et avec peu d'insertions.
La 2e chose est que malgré la présence d'un index celui-ci n'est pas utilisé. Cela est dû au fait que pour que l'index soit utilisé, il faut respecter un certain nombre de règles comme :
- ne pas utiliser l'opérateur IS NULL ou IS NOT NULL dans une colonne indexée (du moins pour un index de type B-tree) ;
- lorsque l'opérateur LIKE est utilisé sur une colonne indexée, ne pas débuter par % ;
- ne pas utiliser de fonction comme upper…
II-C-3-d-iii. Délais d'attente▲
S'il y a un gros écart entre le cpu_time et le elapsed_time, c'est qu'il y a des délais d'attente qui peuvent être divers (accès disques, verrous…).
Pour les verrous, vérifier si le niveau d'isolation est correct afin d'en éviter le maximum. Par exemple avec un mauvais niveau d'isolation, une table entière peut avoir un verrou alors qu'il pourrait être sur seulement une ligne.
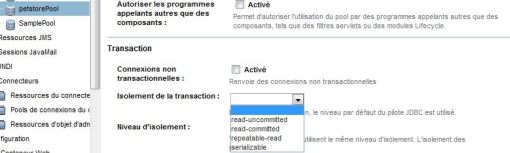
Par exemple sous PostgreSQL :
-
Pour savoir s'il y a des locks
- SELECT * FROM pg_locks ;
- le changement de niveau d'isolation peut se faire avec SET TRANSACTION ISOLATION LEVEL ;
-
ajouter FOR UPDATE à la fin d'une requête SQL pour bloquer une ligne
- SELECT 1 FROM table1 WHERE id_table1 > 5 FOR UPDATE;
Une solution plus générique est d'utiliser les fonctions setTransactionIsolation() de l'interface Connection.
Connection conn = JdbcManager.getConnection();
conn.setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE);Pour éviter les délais dus au réseau, il peut être utile :
- d'utiliser des procédures stockées ;
- minimiser les datas retournés par les requêtes (éviter les Select * from …) ;
- utiliser des caches ;
- …
Pour diminuer les accès disque, il peut être utile de :
- ajouter des index ;
- augmenter le paramètre mémoire du SGBD (SGA/PGA pour Oracle…) ;
- prendre une machine plus puissante ;
- …
II-C-3-d-iv. Optimisation des requêtes SQL▲
Il est temps d'optimiser les requêtes SQL, pour cela allez sur https://sqlpro.developpez.com/cours/optimiser/
De même il faut passer un peu de temps à comprendre comment marche l'optimiseur de requête de la base de données utilisé afin d'avoir les meilleures performances possibles.
Par exemple sous Oracle 9i, les requêtes sont exécutées plus rapidement si les tables sont classées par ordre décroissant (par rapport à la taille) dans les clauses FROM et WHERE.
Une autre solution est d'utiliser la fonctionnalité SQL Optimizer de Quest Toad.
II-C-3-e. Utilisation de JDBC▲
Maintenant que les requêtes, le schéma et le serveur ont été optimisés, il est temps de passer au niveau JDBC.
La première chose à faire si cela est possible est de choisir le bon driver JDBC. En fonction des exigences on pourra prendre le plus rapide ou le plus complet ou …
Après il faut vérifier que toutes les ressources (Connexions, Statements, ResultSets) sont bien fermées lorsqu'elles ne sont plus utilisées. Pour cela on peut utiliser PMD/Findbugs en complément d'une revue de code.
Une fois cela fait il faut choisir le bon nombre de connexions possibles qu'il faudra paramétrer dans le pool de connexion du serveur d'application. Ne pas oublier de changer la valeur du nombre de thread pour qu'elle soit suffisante pour ouvrir assez de connexions.
Regardons un peu plus dans le code source de l'application. Repérons les Statements qui vont être appelés de nombreuses fois et changeons-les par des PreparedStatement. L'avantage des instances PreparedStatement est qu'elles contiennent une instruction SQL déjà compilée.
PreparedStatement pstmt = con.prepareStatement("UPDATE table SET i = ? WHERE j = ?");
pstmt.setLong(1, 123);
pstmt.setLong(2, 100);Si le driver JDBC le permet, on peut activer le cache pour les PreparedStatement.
Plus d'informations sur https://java.developpez.com/faq/jdbc/?page=preparedstatement
Une autre astuce peut être de regrouper les requêtes dans un batch
Connection con = DriverManager.getConnection(.......);
Statement stmt = con.createStatement();
stmt.addBatch("INSERT INTO Adresse .......");
stmt.addBatch("INSERT INTO Contacte .......");
int[] countUpdates = stmt.executeBatch();ou de regrouper les requêtes dans une transaction de la manière suivante :
setAutoCommit(false);
// Executer toute les requêtes
ExecuteUpdate();On retrouvera ces conseils et d'autres sur http://www.precisejava.com/javaperf/j2ee/JDBC.htm
II-C-3-f. Frameworks de persistance : Hibernate▲
Il est important de configurer Hibernate finement et d'utiliser des jointures afin d'éviter trop de requêtes. Pour plus d'informations, reportez-vous à la partie consommation mémoire et sur mon article sur Hibernate
II-C-4. Performance d'affichage d'une page Web▲
Il est important que la partie interface graphique soit fluide et rapide, car cela sera le point d'entrée pour l'utilisateur.
Une des premières choses à faire est de vérifier que les JSP sont précompilés.
Sinon voila quelques astuces :
-
Compression des ressources statiques (images, fichiers flashs, scripts…) afin de réduire le poids général en octets d'un écran
- comparer la taille entre un fichier PNG8 et un fichier GIF et prendre le plus petit,
- supprimer les meta data des fichiers images (EXIFpour les JPEG, chunks pour les PNG…) ;
- mettre en place une politique d'expiration des ressources statiques ;
- activer la compression HTTP afin de réduire les données transitant entre le serveur Web et l'utilisateur final ;
- utiliser des CSS sprite (une seule image découpée par une CSS).
Vous trouverez toutes ces règles et bien plus sur http://developer.yahoo.com/performance/rules.html
On peut utiliser le plugin YSlow afin de nous aider à appliquer ces règles.
Il faut faire attention aux écrans de recherche. Lors d'une exécution d'une recherche, cela ne sert à rien de récupérer tous les résultats si on n'affiche que 10 à la fois. Il existe des frameworks pour cela comme HDPagination.
Pour les applications en JSP avec beaucoup d'écrans, il peut être utile d'augmenter la taille mémoire de la zone Permanent Generation de la JVM (option XX:MaxPermSize).
Continuons un peu avec les JSP.
II-C-4-a. Tuning du serveur d'application pour les JSP▲
- JSP Reload et JSP Development Mode.
Si l'application est en production, on peut désactiver un certain nombre d'étapes du cycle de vie d'une JSP
Par exemple à chaque requête pour une JSP, Tomcat vérifie si cette JSP a été modifiée. Cela est très utile en développement pour ne pas avoir à redéployer l'application à chaque modification de la JSP, mais inutile en production.
Pour gagner du temps, il suffit de modifier les valeurs à false des paramètres development et reloading de la servlet Jasper dans le fichier Tomcat Home/conf/web.xml
<servlet>
<servlet-name>jsp</servlet-name>
<servlet-class>org.apache.jasper.servlet.JspServlet</servlet-class>
...
<init-param>
<param-name>development</param-name>
<param-value>false</param-value>
</init-param>
<init-param>
<param-name>reloading</param-name>
<param-value>false</param-value>
</init-param>
...
</servlet>- genStrAsCharArray.
De même on peut forcer la génération en char arrays de tous les static strings de la JSP. Cela évite l'utilisation de toCharArray() à chaque fois.
<servlet>
<servlet-name>jsp</servlet-name>
<servlet-class>org.apache.jasper.servlet.JspServlet</servlet-class>
...
<init-param>
<param-name>genStrAsCharArray</param-name>
<param-value>true</param-value>
</init-param>
...
</servlet>- Pool de Custom Tags.
Il est possible d'activer un pool pour l'utilisation des Custom Tags.
Pour l'activer, modifions la valeur à true du paramètre enablePooling de la servlet Jasper dans le fichier Tomcat Home/conf/web.xml
<servlet>
<servlet-name>jsp</servlet-name>
<servlet-class>org.apache.jasper.servlet.JspServlet</servlet-class>
...
<init-param>
<param-name>enablePooling</param-name>
<param-value>true</param-value>
</init-param>
...
</servlet>Il faut faire attention si on a de « grosses » JSP, car on peut avoir une exception OutOfMemory. Si cela arrive (ou que lorsqu'on profile l'application, on se retrouve avec BodyContentImpl qui consomme beaucoup de mémoire), on peut paramétrer dans le fichier de démarrage de Tomcat :
- org.apache.jasper.runtime.JspFactoryImpl.USE_POOL = false
- org.apache.jasper.runtime.BodyContentImpl.LIMIT_BUFFER = false
- Désactiver l'AutoDeploy.
Lorsque Tomcat trouve un nouveau WAR dans son répertoire webapps, il le déploie automatiquement.
Pour désactiver cette fonction, il faut modifier le fichier Tomcat Home/conf/server.xml
<Host name="localhost" appBase="webapps" unpackWARs="true"
autoDeploy="false"
xmlValidation="false" xmlNamespaceAware="false">ou dans l'interface d'administration du serveur d'application
II-C-5. Problèmes de thread▲
Les principaux problèmes liés aux threads sont :
- Dead lock : au moins deux threads se bloquent pour accéder à une ressource ;
- Race conditions : au moins deux threads entrent en compétition pour obtenir une ressource et donc le nombre de threads augmente et il faut de plus en plus de temps pour accéder à la ressource ;
- Thread Leak : on crée des thread sans fin jusqu'à avoir un OutOfMemory: unable to create new native thread ;
- Problème de configuration du pool de thread : le nombre de thread configuré dans le pool est supérieur au nombre maximum de thread de la JVM.
La correction de ces problèmes peut aller de simplement changer le nombre de threads disponibles dans le pool de connexion à la modification du code source.
On peut détecter ces problèmes avec :
- VisualVM, Netbeans : Etat des threads ;
- JConsole : Statistiques des contentions des threads.
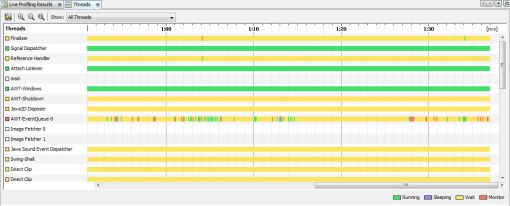
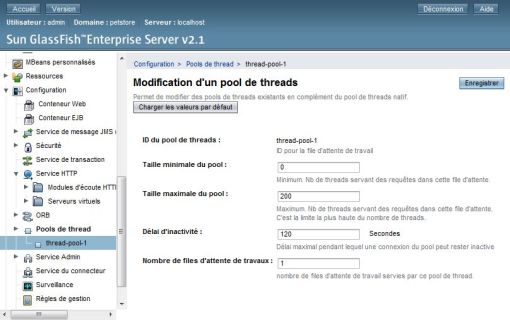
II-C-5-a. Pool de Thread▲
La 1re chose à faire si cela n'a pas déjà été fait est de vérifier le taux d'occupation du pool de thread et le nombre de thread en attente.
En fonction de ces deux valeurs, il faudra augmenter ou diminuer dans le serveur d'application le nombre de threads.
Mark Thomas (Consultant chez SpringSource) conseille dans « Tomcat Optimisation et Performance Tuning » d'avoir en production entre 200 et 800 threads (400 comme valeur de départ).
Il faut bien faire attention à ne pas mettre un nombre trop grand sous peine de surcharger la machine (taux d'occupation processeur inférieur à 80 %) et de surcharger le serveur de bases de données.
II-C-5-b. Serveur web▲
Comme on l'a déjà vu, il faut paramétrer au mieux tous les pools (serveur web, JDBC, serveur d'application) afin de limiter les temps d'attente.
Prenons comme exemple, Glassfish
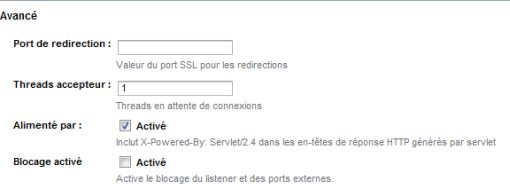
- HTTP Acceptor Threads.
HTTP Acceptor Threads permet de :
- accepter de nouvelles connexions ;
- gérer les nouvelles requêtes associées aux connexions existantes.
Dans la console d'administration de Glassfish
Configuration -> HTTP Service -> HTTP Listeners -> http-listener-1
Puis mettre la bonne valeur dans « Acceptor Threads »
Il est recommandé de mettre 1 Thread pour 1 à 4 cœurs (donc sur un dual core, pas besoin de changer la valeur par défaut qui est de 1).
- HTTP Request Processing Threads.
HTTP Request Processing Threads permet de gérer les requêtes HTTP entrantes.
Dans la console d'administration de Glassfish
Configuration -> HTTP Service -> RequestProcessing
Puis mettre la bonne valeur dans « Thread Count »

II-C-5-c. JVM▲
Certaines options de la JVM permettent d'améliorer les performances.
Par exemple l'option -XX:+UseBiasedLocking de la JVM de Sun (à partir de JDK 5.0_06 et activer par défaut dans JDK 6).
II-C-5-d. Niveau programme▲
D'un point de vue code source, s'il n'y a pas de problème d'algorithme, les deux principaux moyens de réduire les problèmes de threads sont :
- minimiser le périmètre des blocs synchronisés ;
- utiliser des objets non synchronisés (ArrayList, StringBuilder…).
II-C-5-d-i. Blocs synchronisés▲
Les blocs synchronisés permettent de rendre une partie du code accessible à seulement un thread à la fois. L'inconvénient est que si la durée de traitement de ce bloc de code est grande, les autres threads vont devoir attendre.
Pour éviter au maximum cette attente, il faut synchroniser la plus petite partie possible. Par exemple ne pas synchroniser une fonction complète si seulement une seule partie de cette fonction doit être synchronisée.
On peut aussi utiliser ReentrantReadWriteLock afin d'avoir plusieurs locks en lecture en même temps, mais qu'un seul lock en écriture.
De plus, pensez à utiliser java.util.concurrent ou backport-util-concurrent si votre version de la JVM ne le permet pas.
II-C-5-d-ii. Objets non synchronisés▲
Il ne faut utiliser des objets ThreadSafe que si cela est nécessaire afin d'éviter des locks inutiles. Pour détecter une surconsommation de ces objets, on peut faire un profilage de mémoire.
Par exemple pour la HashTable et le Vector.
Si on observe trop de Hashtable en mémoire, vérifier que l'accès synchronisé est nécessaire.
Si cela n'est pas le cas, utiliser plutôt un ArrayList
Sinon préférer ConcurrentHashMap
Si on observe trop de Vector en mémoire, vérifier que l'accès synchronisé est nécessaire.
Si cela n'est pas le cas, utiliser plutôt un HashMap
Sinon préférer LinkedBlockingDeque, ArrayBlockingQueue, ConcurrentLinkedQueue, LinkedBlockingQueue ou PriorityBlockingQueue.
II-C-6. Exception▲
Comme indiqué sur https://blog.developpez.com/adiguba/p1075/java/perfs/exception-et-performances/les exceptions sont coûteuses, mais indispensables. Par contre, n'utiliser les exceptions que pour ce qu'elles ont été créées par les ingénieurs SUN.
Par exemple ne pas utiliser d'exception pour le contrôle de flux comme ci-dessous :
try {
int i = 0;
while (true)
Tableau[i++].lireValeur();
} catch (ArrayIndexOutOfBoundsException e) {
}ou
int i = 0;
while (true) {
i = i + 1;
throw new FinAdditionException();
}Pour repérer ce genre de mauvaise utilisation des exceptions, lors du profilage de la mémoire, vérifier le nombre d'allocations d'objets Exception ou utiliser la fonction de Yourkit Java Profiler.
Penser aussi à bien configurer le niveau de log.
II-C-7. Utilisation de cache▲
S'il n'y a pas de problème de consommation de mémoire, il peut être utile d'ajouter des caches entre certaines couches de son application.
Pour que les performances du cache soient optimales, il faut faire attention à la taille des caches.
II-C-8. flux d'entrées/sorties▲
Pour tout ce qui est flux d'entrées/sorties, les buffers sont utiles.
Par exemple préférez utiliser l'API java.nio à la place de l'API java.io.
Attention ce n'est pas toujours le cas http://www.theserverside.com/news/thread.tss?thread_id=48449
Bien régler le niveau de log peut être utile.
On peut surveiller les entrées/sorties avec :
- Linux : iostat… ;
- Solaris : DTrace… ;
- Windows : Filemon…
II-D. Quelques astuces▲
II-D-1. Copie de tableau▲
Pour la copie de tableau, préférer l'utilisation de System.arrayCopy
II-D-2. Utiliser la dernière JVM si possible▲
Si cela est possible, pensez à utiliser la dernière version de la JVM, car Sun améliore régulièrement les performances de sa JVM, active un certain nombre d'options au fur et à mesure et ajoute des outils.
Par exemple :
- à partir de Java 1.5, plus besoin de jvm -server car la JVM détecte automatiquement le contexte ;
- l'option -XX:+UseBiasedLocking est activé seulement à partir de la version 6 ;
- …
II-E. Conclusion▲
On a vu qu'atteindre l'objectif de performance que l'on s'est fixé fait intervenir de nombreuses connaissances à diverses phases du projet (développement, paramétrage…). Sur les applications exigeantes en terme de performance, l'aide d'experts (DBA…) est un gros plus pour le succès du projet. Comme pour les autres types de recettes (fonctionnelle…), la méthodologie est très importante.
Et surtout mesurer les performances avant d'optimiser.
Après il faut se méfier des « trucs et astuces » que l'on trouve sur le net (y compris cet article), car elles dépendent du contexte qui n'est pas forcément le même que sur vos projets.
N'hésitez pas à compléter vos connaissances (cache EJB, JVM d'IBM, création de jeux de test…).
II-F. Remerciements▲
Remerciements à DD77 pour sa relecture et son aide.
Remerciements à Milamber pour sa relecture et son aide.
Remerciements à Dut pour sa relecture orthographique.
Remerciements à ClaudeLELOUP pour sa relecture orthographique.
II-G. Références▲
Documentations SUN :
http://java.sun.com/performance/reference/whitepapers/6_performance.html
http://java.sun.com/docs/hotspot/HotSpotFAQ.html
Forum de JBoss sur la performance
Forum de JBoss
Blog de Ippon Technilogies où il y a un certain nombre d'articles sur les fuites mémoires
http://blog.ippon.fr/
Blog de Xebia
http://blog.xebia.fr/
Profiler de Netbeans
http://profiler.netbeans.org/index.html
Profiler commerciaux
YourKit
JProfiler
Jprobe
Apache JMeter
http://groups.google.com/group/jmeter-fr/topics?hl=fr
http://blog.milamberspace.net/
HP LoadRunner
Site officiel