




I. Un peu de théorie▲
Pour la partie théorique et quelques exemples, je vous laisse aller sur le site officiel et sur mon précédent article sur developpez.com.
II. Passons à la pratique▲
II-A. Présentation du cas de test▲
Dans cet article nous allons nous pencher sur la création de plusieurs jeux de données pour l'application démo PlantsByWebSphere livrée avec IBM WebSphere 8. Nous utiliserons une base de données MySQL en remplacement de Derby.
PlantsByWebSphere est une démonstration de boutique en ligne comme vous pouvez le voir sur cette capture d'écran.
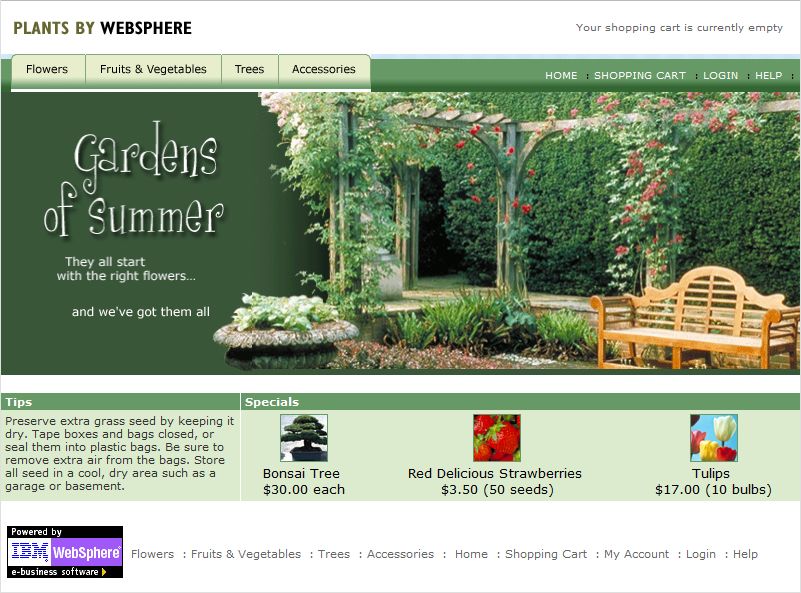
On remarque que :
- les produits sont divisés en quatre catégories (Flowers, Fruits & Vegetables, Trees et Accessories) ;
- l'application gère des comptes clients ;
- l'application gère un panier d'achats.
Regardons d'un peu plus près le schéma de la base de données.

Et son code SQL.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. 98. 99. 100. 101. 102. 103. 104. 105. 106. 107. 108. 109. 110. 111. 112. 113. 114. 115. 116. |
Comme on peut le voir, le schéma de la base de données n'est pas ce qui se fait de mieux, mais nous permettra d'avoir une bonne vision de l'utilisation de Benerator.
Après la découverte du schéma de la base de données et du fonctionnement Benerator, regardons comment créer le fichier XML de description du projet.
II-B. Paramétrage de la base de données cible et de la volumétrie du jeu de données▲
Mais avant cela, nous allons créer deux fichiers properties afin de regrouper les informations sur :
- la base de données ;
- la volumétrie cible.
Les informations sur la base de données seront dans le fichier mysql\PlantsByWebSphere.mysql.properties
|
Sélectionnez 1. 2. 3. 4. 5. |
Les informations sur les volumétries cibles seront dans les fichiers de type PlantsByWebSphere.{volumetrie}.properties
Par exemple pour un poste de développement, le fichier se nommera PlantsByWebSphere.development.properties
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. |
II-C. Création du fichier de description de Benerator▲
- Commençons par l'entête du fichier.
|
Sélectionnez 1. |
- Importons les domaines nécessaires et la bonne plate-forme.
Définissons des valeurs par défaut pour le type de volumétrie et le type de base de données cible.
Valeur par défaut
- Chargeons les deux fichiers properties que l'on a créés.
Récupération des valeurs pour la volumétrie et la base de données cible
- Définissons l'URL de la base de données (ne pas oublier d'ajouter les drivers dans le classpath si nécessaire).
Afin d'éviter les mauvaises surprises, partons d'une base vide (drop + create) à l'aide de deux scripts SQL.
Drop des tables avant leurs créations
- Créons deux générateurs de nombres auto-incrémentés pour les utiliser comme clé primaire. Maintenant, en fonction de ce que l'on veut tester, il nous reste plusieurs choix possibles comme :
- simuler des tests avec un catalogue de produits plus grand que celui défini par défaut ;
- simuler des tests à l'ouverture de la boutique en ligne ;
- simuler des tests après plusieurs jours de fonctionnement (ce qui correspond à avoir déjà des clients et des commandes en base de données) ;
- simuler plusieurs combinaisons des cas précédents.
Ces choix impacteront le volume et la répartition des données en base et donc les résultats des tests.
Dans notre cas, nous allons regarder comment créer des données pour chaque table.
- Commençons par ajouter des articles en base (table INVENTORY).
Chargeons les images des articles en mémoire afin de pouvoir remplir le champ IMGBYTES. L'objectif du jeu de données étant une campagne de tests de charge, nous ne nous soucierons pas de la correspondance entre l'image et le produit.
Afin de contrôler le plus finement possible la répartition des articles, nous les traiterons catégorie par catégorie (champ CATEGORY).
Chaque catégorie sera générée de cette façon (ici pour la catégorie des Flowers)
generate type="INVENTORY" count="{inventory_cat0_count}" consumer="db" pageSize="{taillePaquet}" >
En fonction de la catégorie et de l'objectif du test, on pourra modifier les paramètres suivants :
- count ;
- QUANTITY ;
- ISPUBLIC.
Je vous laisse créer les autres articles pour les trois catégories restantes (CATEGORY aura pour valeurs : 1, 2 et 3).
- Créons à l'identique de l'original la table SUPPLIER.
- Créons des comptes clients (table CUSTOMER). Comme on peut le voir, on utilise les domaines Personet Address afin d'avoir des données réalistes.
Il nous reste à créer des commandes clients (tables ORDER1, ORDERITEM et IDGENERATOR).
- Remplissons la table ORDER1.
- Puis la table ORDERITEM.
Mettons à jour le prix de chaque commande (champ PROFIT de la table ORDER1).
On utilise la fonction SQL IFNULL de MySQL afin d'être sûr de mettre une valeur non null dans le champ PROFIT.
Une autre solution est d'utiliser un subSelector à la place de la combinaison de selector et cyclic="true".
Pour la dernière table IDGENERATOR, on va utiliser les capacités de Benerator à importer des fichiers CSV.
Importons le fichier CSV idgenerator.import.csv.
Puis mettons à jour la valeur du champ IDVALUE.
Une autre solution est de tout faire lors de l'importation du fichier CSV à l'aide du mot clé condition.
Il ne reste plus qu'à exécuter Benerator pour générer notre jeu de données.
Notre fichier XML de description est prêt et je vous laisse le paramétrer au mieux pour l'objectif de vos tests.
Ma conclusion sur cet outil est toujours la même :
- il est pratique ;
- pilotable en ligne de commande et donc très flexible pour son intégration dans un processus ;
-
larges possibilités :
- générer un jeu de données à partir de rien ;
- anonymiser un jeu de données ;
- traitement de données existantes comme pour un ETL ;
- création de fichiers d'entrée pour un test de charge (création de login/password…) ;
- possibilité d'utiliser le même fichier XML de configuration de Benerator pour divers environnements (test, développement,préproduction …) à l'aide de fichiers properties ;
- documentation complète ;
- développement actif ;
- gratuit ;
- open source ;
- support par le développeur ;
- extensible.
III. Conclusion ▲
Dans ce tutoriel, nous avons présenté l'outil Benerator. C'est un outil de génération de données open source, dont le but premier est de générer d'importants lots de données pour des tests.
Benerator génère des entités abstraites sur la base d'un fichier de configuration. Les formats suivants sont supportés comme sources de données pour la génération : Comma Separated Values (CSV), XML, flat file, database et Excel sheet.
IV. Remerciements▲
Nous tenons à remercier Claude Leloup pour sa relecture de cet article et Laethy pour la mise au gabarit.