




I. Un peu de théorie▲
L'architecture d'un moteur de base est devenue très complexe comme le montre le schéma ci-dessous (notons que ce n'est qu'une description simplifiée de l'architecture d'Oracle).
La complexité est telle que l'expertise sur une version d'Oracle est remise en cause dès la sortie de la version suivante.
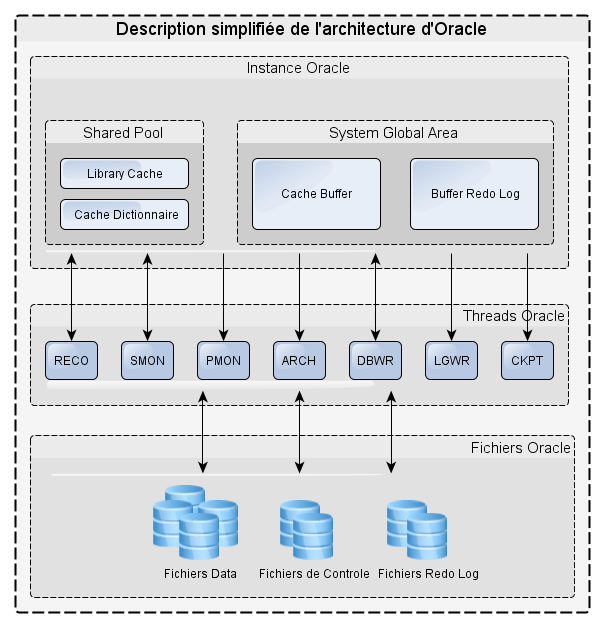
Chaque partie de cette architecture peut être paramétrée afin de s'adapter au mieux à l'utilisation de la base de données.
Si on ajoute que les données stockées en base sont l'un des éléments les plus importants d'une application et celui qui pose le plus de problèmes de performance, on comprend l'importance de faire des tests de charge sur le serveur de bases de données.
Pour ceux qui ne sont pas encore convaincus par l'importance de faire du tuning de l'architecture du moteur de base de données, ci-dessous un exemple de temps de réponse d'une requête SQL sur un Oracle sans tuning (la SGA, un des caches de la base de données Oracle, n'est pas bien configurée) par rapport à un Oracle optimisé (on a augmenté la taille de la SGA pour qu'elle soit cohérente par rapport à la taille des données stockées en base).
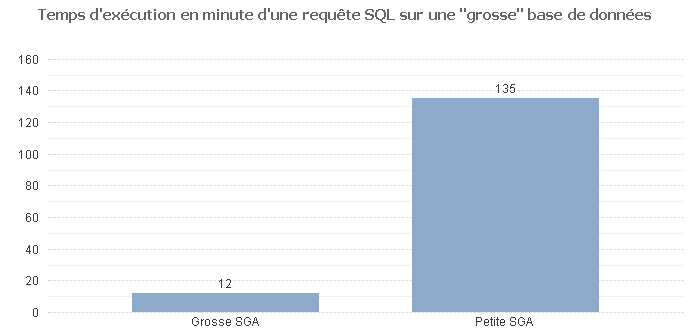
Comme on peut le voir, cela vaut le coup de passer un peu de temps à optimiser Oracle à l'aide d'un test de charge.
Regardons maintenant comment JMeter permet de tester un serveur de base de données.
II. Mise en place avec JMeter▲
JMeter étant un programme Java, l'accès à une base de données se fait à l'aide du protocole JDBC.
La première chose à faire est donc de mettre le pilote JDBC dans le ClassPath de JMeter si ce n'est pas déjà fait (en pratique, on déposera le fichier pilote .jar dans JMETER_HOME/lib/).
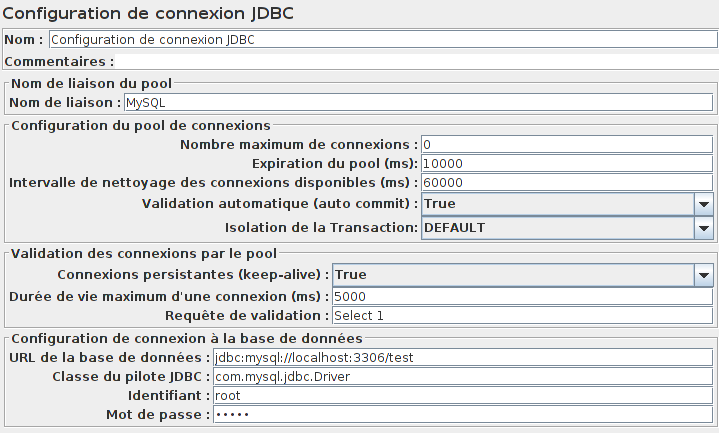
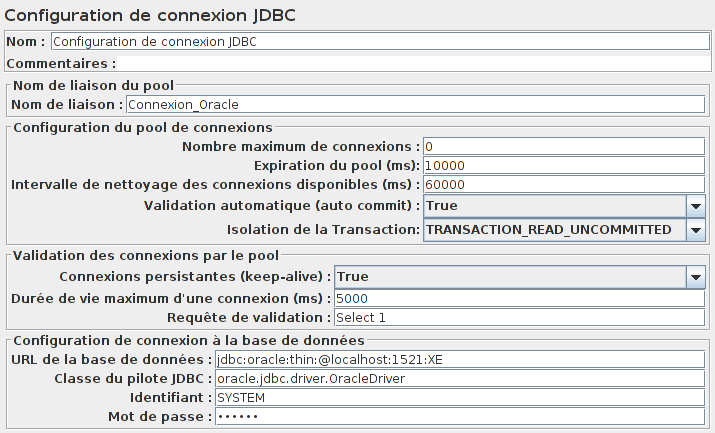
Une fois cela fait, il faut configurer la connexion à la base avec l'élément Configuration de connexion JDBC.
Cela va nous permettre de configurer la chaîne de connexion à notre base de données (URL, port, identifiant de connexion, mot de passe, etc.).
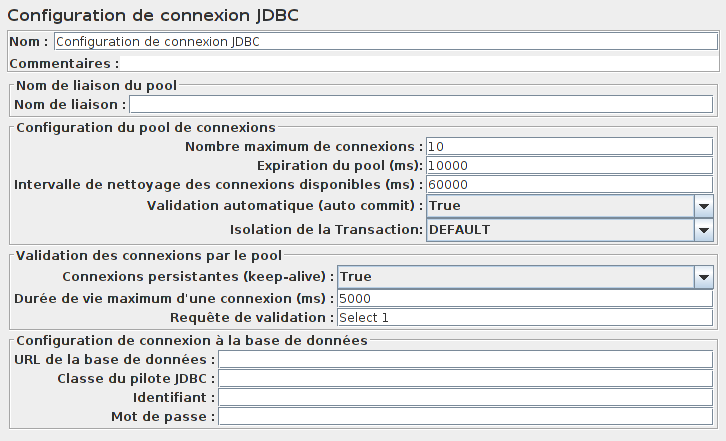
Cet élément est composé de quatre parties nommées Nom de liaison du pool, Configuration du pool de connexions, Validation des connexions par le poolet Configuration de connexion à la base de données.
Leurs noms étant parlants, nous ne nous attarderons donc pas plus.
Cependant, il est important de faire attention aux parties Configuration du pool de connexions et Validation des connexions par le pool afin de ne pas surcharger JMeter (en particulier le nombre maximum de connexions) et la base de données (niveau d'isolation de la Transaction, auto commit et requête de validation).
Bien sûr, il est possible d'avoir plusieurs éléments Configuration de connexion JDBC qui pointent sur plusieurs bases de données.
Maintenant, on peut passer aux requêtes SQL elles-mêmes à l'aide de l'élément Requête JDBC.

Dans un premier temps, on choisit sur quelle base de données les requêtes vont être lancées à l'aide du champ Nom de liaison (nom défini dans l'élément Configuration de connexion JDBC).
Comme on peut le voir dans la liste Type de requête, tous les types de requêtes peuvent être réalisés (UPDATE, SELECT, DELETE, INSERT, appel de procédure stockée, etc.).
À l'aide de ces deux éléments, on peut tester tout type de base de données (la seule exigence est la présence d'un pilote JDBC pour la base de données cible) avec toutes les requêtes SQL imaginables.
III. Méthodologie▲
Avant de passer à des exemples concrets, il est important d'avoir une méthodologie afin de réaliser des tests pertinents.
Quelques conseils qu'il est préférable d'intégrer à votre processus :
Chose importante lors d'un test d'une base de données, s'assurer qu'elle est isoproduction, à défaut s'assurer que la différence est acceptable et que le test reste utilisable.
Par isoproduction il faut comprendre deux choses :
- Le paramétrage du moteur de base de données doit être identique à celui de production (s'il existe).
- Le volume des données en base doit être lui aussi le plus proche de la réalité (le plus simple est d'avoir une sauvegarde de ce qu'il y a en production ou si on part de zéro, d'avoir une idée de la future volumétrie).
Pour les sceptiques ou curieux, on peut voir sur le graphique suivant, le temps de réponse de la même requête SQL exécutée sur des volumes de données différents.
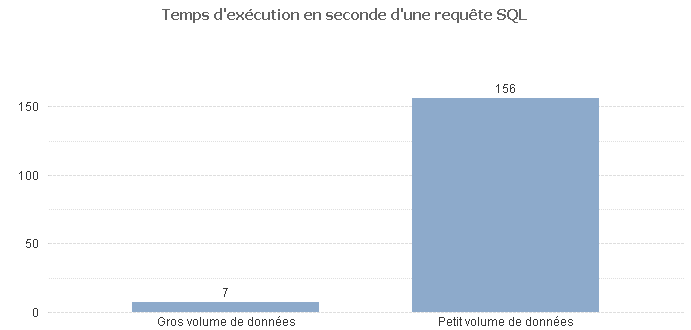
Maintenant que nous avons une base de données isoproduction, penchons-nous sur le plan de test.
Dans notre plan de test, il faut prendre en compte la durée des tests et la diversité des requêtes d'entrée.
De nos jours, il y a forcément des caches dans l'architecture que l'on va tester (que cela soit au niveau du moteur de base de données ou au niveau d'autres composants de l'architecture technique).
Les caches sont conçus pour éviter que les mêmes traitements lourds (requêtes SQL, etc.) avec les mêmes paramètres (valeurs des paramètres, etc.) soient exécutés à chaque fois. Pour cela un cache stocke le résultat du traitement lourd.
Cela implique que le cache sera inutile si la durée de test est trop courte, car il n'aura pas le temps de se remplir pour être utile. Et le cache sera trop utilisé si la diversité des requêtes envoyées (et donc leurs types et leurs paramètres) est trop réduite. Inversement le cache sera inutile si le jeu de données est trop diversifié.
IV. Mise en pratique avec JMeter▲
Passons à la pratique.
IV-A. Exemple 1 : test de charge d'une base de données▲
Démarrons par un exemple simple (que nous complexifierons au fur et à mesure) qui consiste à tester une base de données sous MySQL à l'aide d'une requête SQL.
Occupons-nous dans un premier temps des requêtes SQL de type SELECT.
Commençons par configurer notre connexion à MySQL à l'aide de l'élément Configuration de connexion JDBC.
Pour MySQL, l'URL de la base de données doit être de la forme jdbc:mysql://host:port/dbnom et la classe de pilote JDBC égale à com.mysql.jdbc.Driver.
Dans notre cas, la base MySQL est installée en local et par défaut sur la même machine que JMeter (à éviter absolument lors de vrais tests), son URL sera jdbc:mysql://localhost:3306/test.
On règle à zéro le nombre maximum de connexions afin que chaque thread ait sa propre connexion.
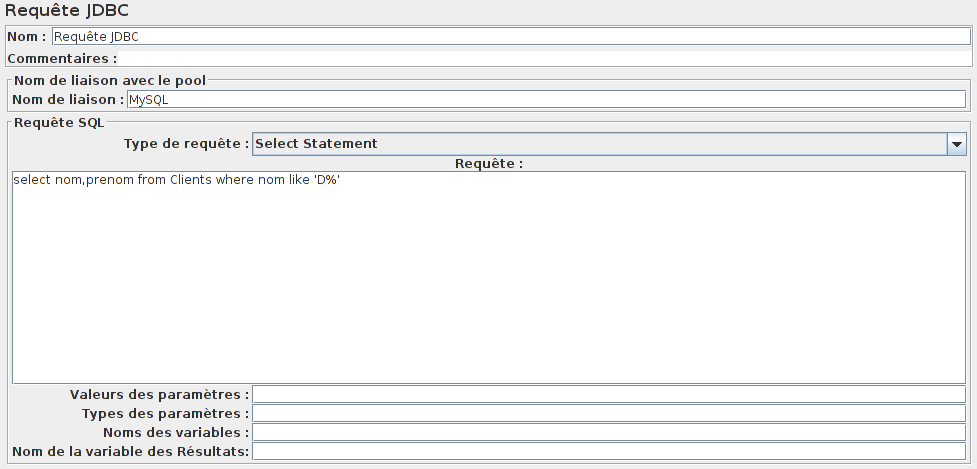
Maintenant, ajoutons une Requête JDBC afin d'exécuter notre fameux SELECT.
Mettre le nom de la connexion qui a été défini avant.
Choisir Select Statement comme type de requête SQL
Remplir le champ Requête avec notre select (ici select nom,prenom from Clients where nom like 'D%').
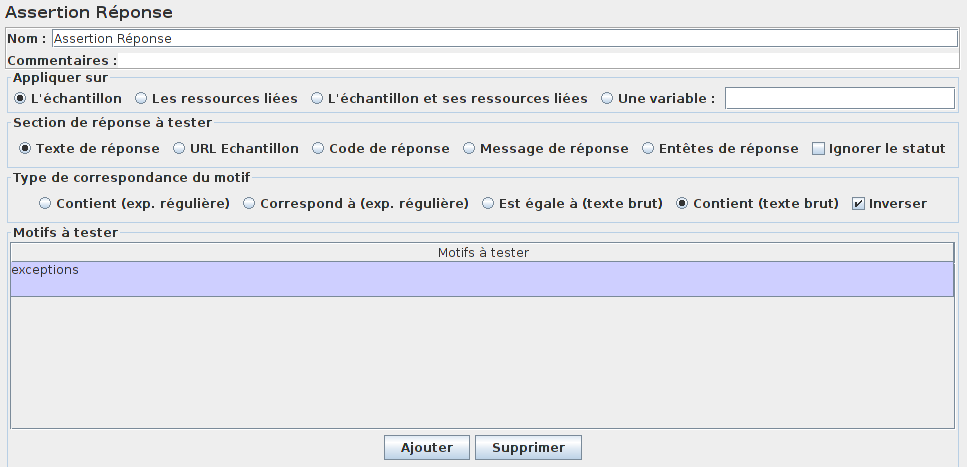
Ajouter une assertion afin de contrôler la bonne exécution de notre requête.
Dans notre cas, lorsqu'il y a une erreur d'exécution, la réponse contiendra l'expression exceptions.
Dans l'état actuel, le script ne couvrira qu'une partie infime d'un bon plan de test, puisqu'avec une seule requête SQL, on testera surtout les caches.
Heureusement, nous disposons d'une liste des principales requêtes SQL de type SELECT exécutées.
Un moyen simple d'intégrer ces nouvelles requêtes à notre script est d'utiliser un élément Source de données CSV.
Pour cela on va mettre toutes les requêtes dans un fichier CSV.
Extrait du fichier CSV :
2.
3.
4.
5.
6.
7.
req_sql
select nom,prenom from Clients where nom like 'D%'
select nom from Clients
select nom,prenom from Clients where sex = 'MALE'
select nom,prenom from Clients where nom like 'T%'
select nom,prenom from Clients where sex = 'FEMALE'
select nom,prenom,mail,code_postal from Clients where code_postal = '58418'
On va renseigner le nom de notre fichier CSV dans le champ Nom de fichier de l'élément Source de données CSV.
Ne pas oublier de changer la valeur du délimiteur de virgule en, par exemple, point-virgule afin qu'il n'y ait pas de problème avec les virgules qui composent nos requêtes.
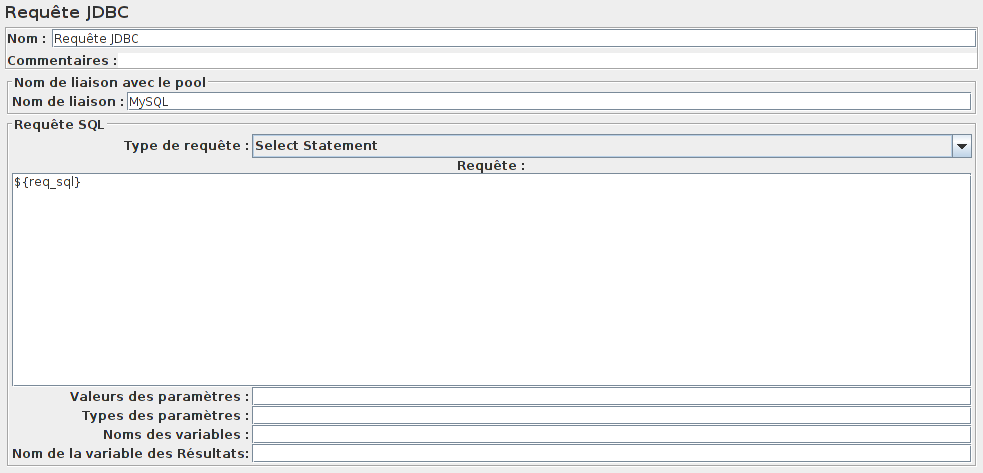
Ici, on n'a pas besoin de définir le nom de la variable où sera stockée la requête afin d'être utilisée par la suite, car elle existe déjà dans notre fichier CSV.

Il ne nous reste plus qu'à remplacer la requête dans le champ Requête de l'élément Requête JDBC par notre variable ${req_sql}.
Afin de vérifier que cela fonctionne, on ajoute un élément Arbre de résultats à notre plan de test (ne pas oublier de le désactiver pour la suite lorsqu'on fera un test de charge).
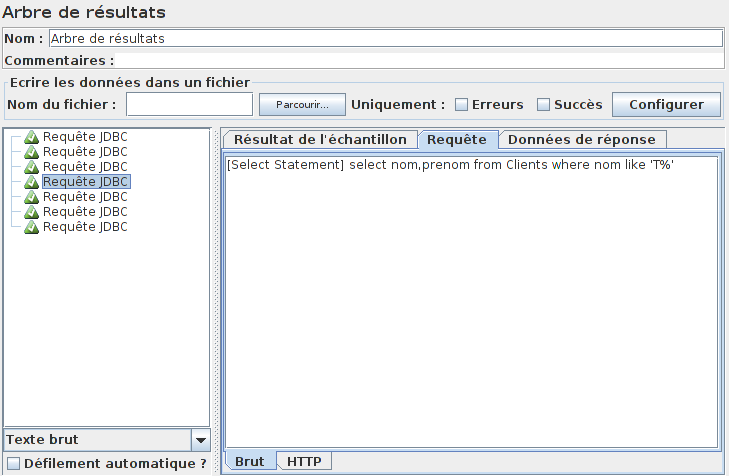
Voilà qui est beaucoup mieux, mais les requêtes restent statiques et, au bout d'un moment (plus ou moins long en fonction du nombre de requêtes SQL dans le fichier CSV), elles se retrouveront toutes dans le cache.
Afin d'éviter ce problème et de rendre notre test plus réaliste, on va rendre dynamiques nos requêtes SQL.
Pour commencer, on va regrouper nos requêtes par famille ayant la même forme syntaxique.
Dans notre cas nous avons deux familles :
other
2.
3.
select XXXXXXX from XXXXX where XXXXX
select XXXXXXX from XXXXX
On aura donc besoin de deux Requêtes JDBC.
Maintenant, pour chaque groupe de requêtes, on va noter ce qui peut être variabilisé.
Par exemple :
sql
select nom, prenom from Clients where nom like 'D%'
deviendra :
other
select {liste_selection} from {table} where {clause where}
Toutes ces variables seront dans un fichier CSV.
Extrait du fichier CSV :
other
2.
3.
4.
5.
6.
liste_selection_grp1;table_grp1;clause_where_grp1
nom,prenom;Clients;nom like 'D%'
nom,prenom;Clients;sex = 'MALE'
nom,prenom;Clients;nom like 'T%'
nom,prenom;Clients;sex = 'FEMALE'
nom,prenom,mail,code_postal;Clients;code_postal = '58418'
On modifie notre élément Source de données CSV afin qu'il pointe sur notre nouveau fichier CSV.
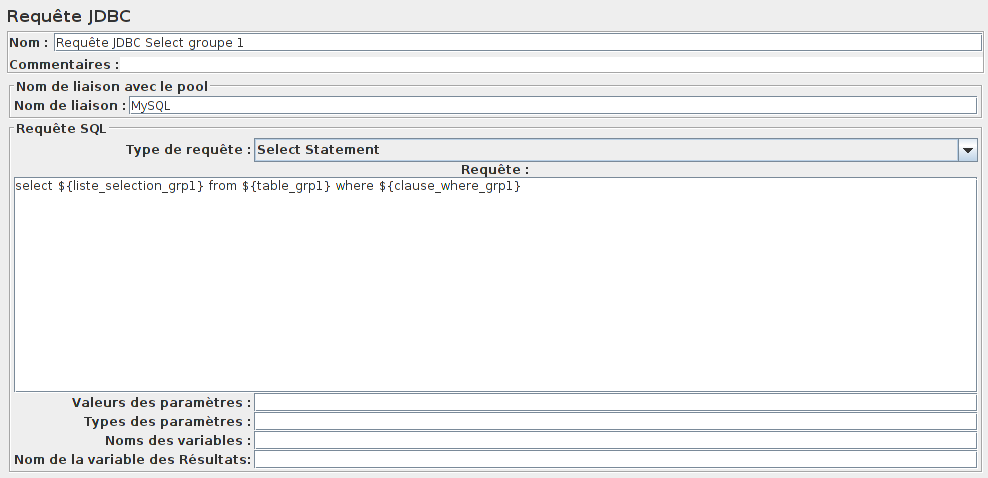
Enfin on modifie notre champ requête qui devient :
other
select ${liste_selection_grp1} from ${table_grp1} where ${clause_where_grp1}
On fait la même chose pour le deuxième groupe de requêtes SQL.
Extrait du fichier CSV :
other
2.
liste_selection_grp2;table_grp2
nom,prenom;Clients
Ajoutons l'élément Contrôleur d'Ordre aléatoire afin d'ajouter encore un peu plus de réalisme en simulant des utilisateurs avec des comportements différents.

Avec encore un peu d'effort, on peut encore rendre plus réalistes les clauses WHERE de nos requêtes SQL.
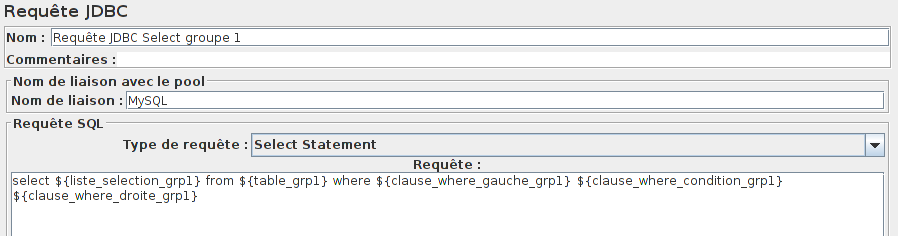
On remarque que la clause WHERE peut être séparée en plusieurs parties.
other
{clause where} = {clause where gauche} {clause where condition} {clause where droite}
Avec la même méthodologie que précédemment, on peut affiner notre fichier CSV et notre Requête JDBC pour ainsi multiplier les requêtes possibles avec un jeu de données réduit (il suffira d'utiliser un script qui génère notre fichier CSV en combinant les valeurs possibles).
Par exemple.
Extrait du fichier CSV :
other
2.
3.
liste_selection_grp1;table_grp1;clause_where_grp1
nom,prenom;Clients;nom like 'D%'
nom,prenom,mail,code_postal;Clients;code_postal = '58418'
Devient :
Extrait du fichier CSV :
other
2.
3.
4.
5.
liste_selection_grp1;table_grp1;clause_where_gauche_grp1;clause_where_condition_grp1;clause_where_droite_grp1
nom,prenom;Clients;nom;like;'D%'
nom,prenom,mail,code_postal;Clients;code_postal;=;'58418'
nom,prenom;Clients;code_postal;=;'5841'
nom,prenom,mail,code_postal;Clients;nom;like;'D%'
Dans la majorité des cas, il y a des utilisateurs avec des droits de modification (appelons-les administrateurs) qu'il faudra simuler. Rien de plus simple avec JMeter.
Afin de séparer les deux types d'utilisateurs, on va créer un autre Groupe d'unités. On pourra ainsi paramétrer de manière fine chaque groupe.
Par exemple si on sait qu'il y a 24 % d'utilisateurs qui ont des droits de modification, il sera facile de trouver la valeur du Nombre d'unités pour chaque groupe.
Afin d'éviter de faire des UPDATE qui ne mettent rien à jour, les conditions de nos requêtes UPDATE seront les résultats de requêtes SQL exécutées juste avant par nos UPDATE.
Imaginons que ces utilisateurs puissent modifier le numéro de téléphone des clients.
Dans un premier temps nous devons récupérer l'identifiant de la personne dont le numéro de téléphone va être modifié.
Utilisons un élément Requête JDBC afin d'exécuter cette requête SQL. On pourra prendre select id_client from Clients where nom like 'F%' comme requête SQL (je vous laisse appliquer ce que l'on vient d'apprendre pour rendre plus dynamique cette requête SQL).
Ne pas oublier de récupérer les résultats de la requête SQL.
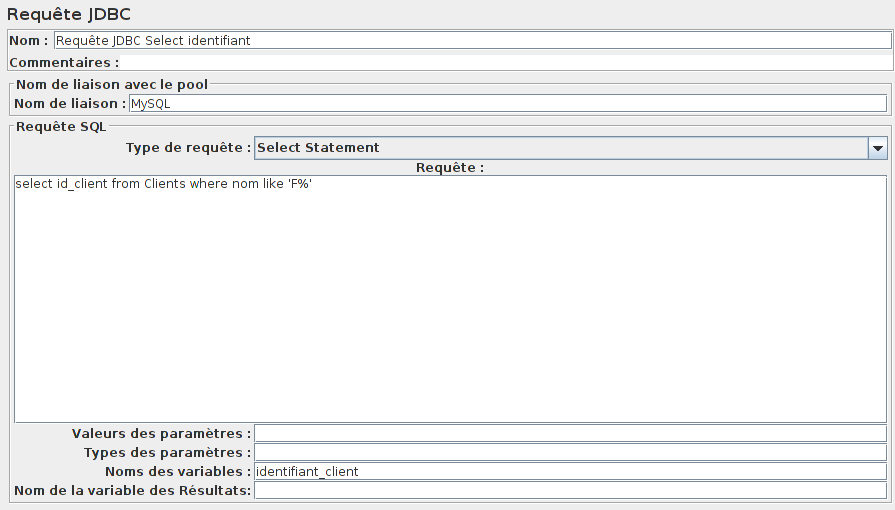
Comme on peut le voir, la requête récupère plusieurs identifiants.
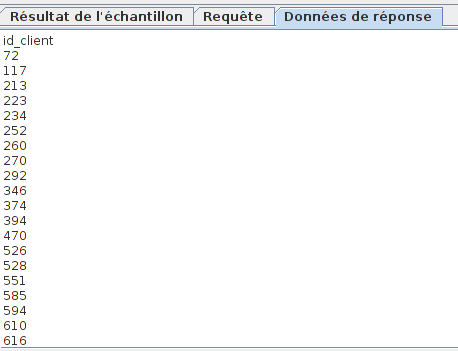
On a le nombre de réponses dans la variable identifiant_client_#
On va choisir un identifiant au hasard dans la liste retournée. Pour cela on va utiliser la fonction __Random de JMeter.
La formule ${_Random(1,${identifiant_client#},identifiant_client_final)} mise dans un échantillon BeanShell nous permettra de réaliser ce que l'on veut en mettant l'identifiant dans la variable identifiant_client_final.
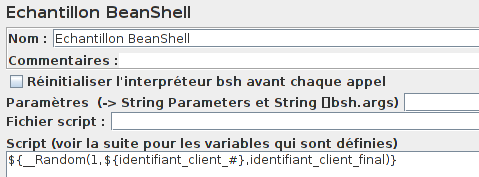
Maintenant que l'on a notre identifiant de client, il nous faut un nouveau numéro de téléphone.
Utilisons l'élément Variable aléatoire.
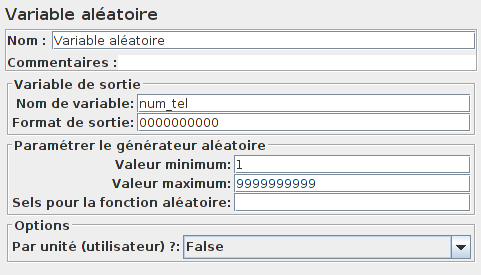
Il ne nous reste plus qu'à utiliser la variable identifiant_client_final et notre nouveau numéro de téléphone dans notre update à l'aide d'un autre élément Requête JDBC.
Notre UPDATE sera :
other
update Clients set telephone_fixe = ${num_tel} where id_client = ${identifiant_client_final}
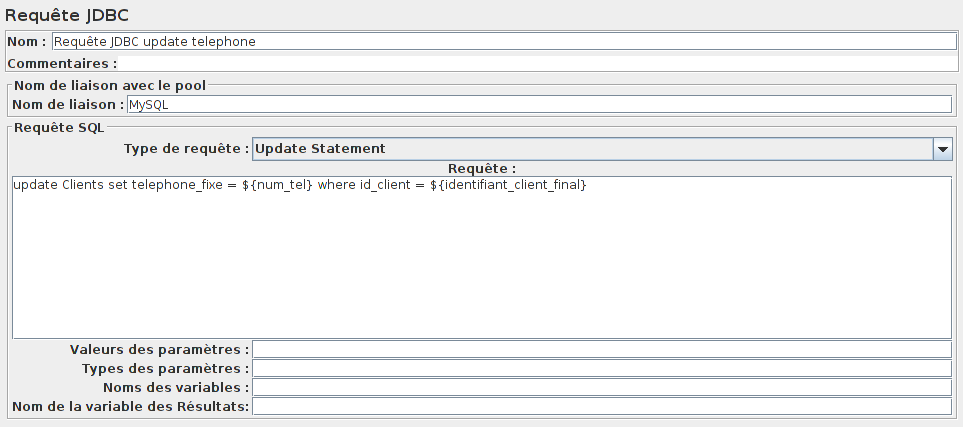
Les administrateurs font aussi des requêtes SQL de type SELECT, et l'on connaît la proportion des SELECT et des UPDATE.
Afin d'implémenter cette proportion, on va utiliser l'élément Contrôleur Débit de JMeter.
Par exemple ici, on définit que les requêtes UPDATE représentent 30 % des requêtes totales.
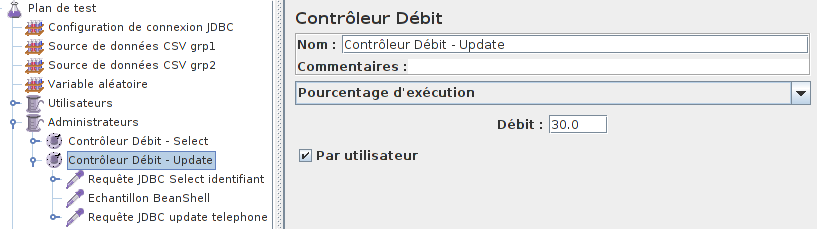
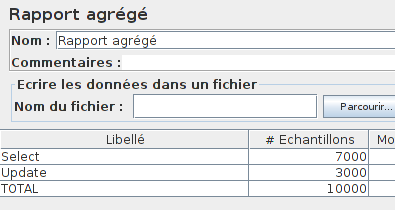
On peut vérifier à l'aide d'un Rapport agrégé que cela est bien respecté (j'ai regroupé les requêtes à l'aide d'un Contrôleur Transaction afin de faciliter la lecture des résultats).
Une bonne pratique dans le développement logiciel est la philosophie DRY (Don't Repeat Yourself). Malheureusement, si on regarde notre dernière modification du script, on peut voir qu'il y a des duplications dans la partie du script qui exécute les requêtes SELECT.
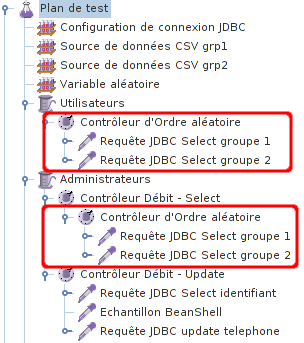
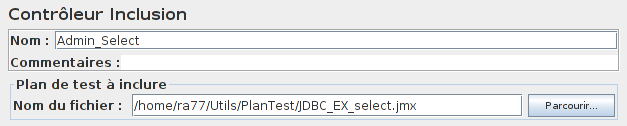
Pour éviter cette duplication, on va utiliser l'élément Contrôleur Inclusion qui nous permet d'inclure un script dans un autre script.
La première chose à faire est de sauvegarder la partie dupliquée dans un fichier au format JMeter.
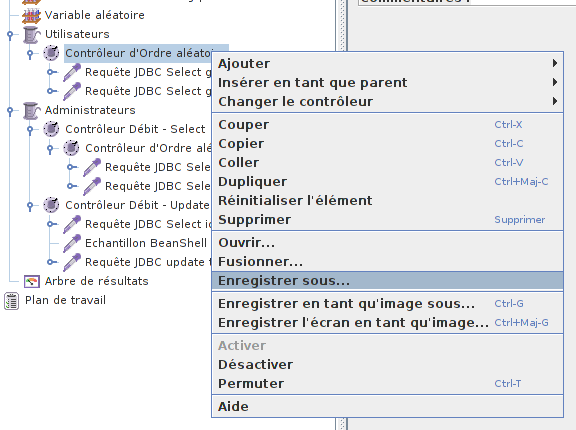
Maintenant, il suffit de remplacer dans le script les parties dupliquées par des Contrôleur Inclusion.
![[ALT-PASTOUCHE]](./images/image047.png)
Les faire pointer sur notre script sauvegardé précédemment.
On aurait pu s'arrêter là tout en ayant répondu aux besoins d'un test de charge de notre serveur de base de données, mais comme je pense que l'industrialisation des tests est quelque chose d'important, nous allons faire quelques modifications. Ceci aura pour but de faciliter l'intégration de notre script dans une usine logicielle.
Le tout à l'aide de la fonction ${__P(xxx,yyy)} avec xxx le nom de la variable et yyy sa valeur par défaut.
Par exemple pour le groupe d'unités « Administrateurs ».

Ici, on définit que par défaut il y a une unité qui exécute une itération et que la durée de montée en charge est d'une seconde.
Lors de l'exécution de JMeter en ligne de commande, si l'on veut changer les valeurs de ces paramètres, il suffira d'ajouter -J{nom de la variable}={valeur de la variable}.
Par exemple.
other
jmeter -n -l resultats.csv -t scenario.jmx -JnbUnites=10 -JrampUp=20 -JnbIterations=100
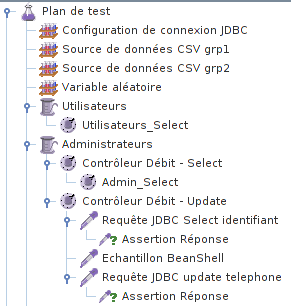
Notre plan de test enfin complet.
IV-B. Exemple 2 : Preuve de faisabilité▲
Dans le tuning SQL, les index tiennent une bonne place, mais comme souvent il y a un coût. Pour démontrer ce coût, on va réaliser un POC (Proof Of Concept = Preuve de faisabilité) à l'aide de JMeter.
Cette fois-ci, notre test sera réalisé sur Oracle 11g Express Edition (ne pas oublier d'ajouter les drivers JDBC d'Oracle dans le ClassPath de JMeter).
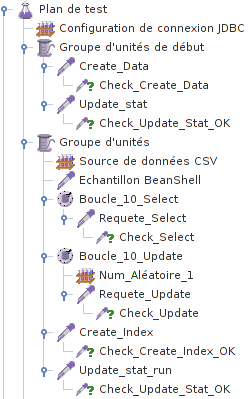
Notre plan de test final ressemblera à celui-ci.
Commençons par définir la connexion à Oracle à l'aide de l'élément Configuration de connexion JDBC.
Dorénavant, on peut se connecter à notre base de données, mais malheureusement elle est vide.
Résolvons ce problème grâce à l'élément Groupe d'unités de début qui va nous permettre d'exécuter des commandes au début du test.
Ajoutons-lui un élément Appel de processus système afin de remplir cette base de données (par le chargement d'une sauvegarde, par la création de données à l'aide d'outils ou de commandes SQL, etc.).
Afin d'être sûr que les statistiques de notre base de données sont à jour, nous allons demander à Oracle de le faire par la procédure SQL dbms_stats.gather_table_stats('SYSTEM','Clients',cascade=>TRUE).
Comme pour l'exemple précédent, on va utiliser l'élément Requête JDBC.
L'appel d'une procédure SQL pour Oracle avec cet élément se fait de la manière suivante.
Le type de requête SQL doit être à Callable Statement.
Le champ Requête doit être :
other
2.
3.
begin
{call proçedure SQL}
end;
Dans notre cas, on aura :

Ne pas oublier de tester la réponse avec un élément Assertion Réponse.
En cas d'erreur, Oracle retourne un code d'erreur commençant par ORA-
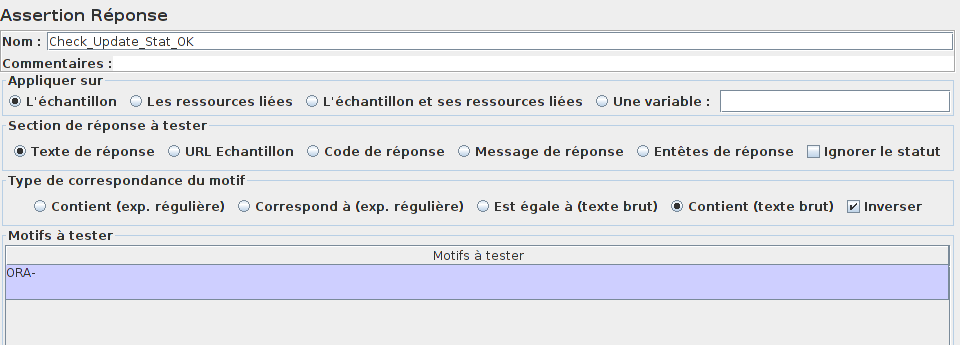
Notre base de données est prête.
On veut que notre test tourne tant qu'il y a des index à créer.
Pour cela nous allons utiliser un élément Groupe d'unités dont le nombre d'itérations sera égal à l'infini et le nombre d'unités à 1.
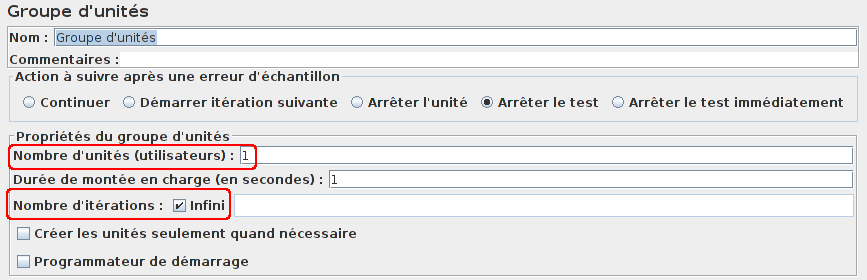
Les requêtes de création d'index seront dans un fichier CSV.
Et pour arrêter notre test à la fin du fichier CSV (et donc à la dernière création d'index), il suffira de le préciser dans l'élément Source de données CSV.
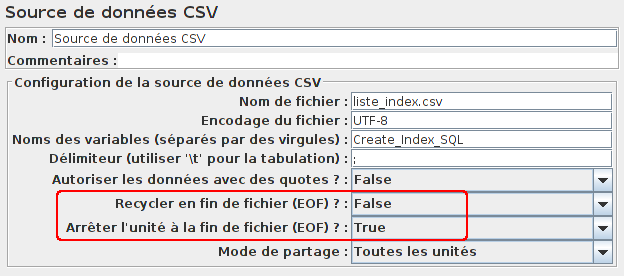
Maintenant, passons à l'exécution de nos requêtes SELECT. À l'aide de l'élément Contrôleur Boucle nous allons réaliser dix requêtes afin d'avoir des temps de réponse plus précis.
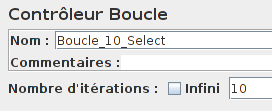
Il suffit d'ajouter notre requête SELECT.
Faisons de même pour les UPDATE. Mais cette fois-ci nous allons utiliser des Prepared Update Statement comme type de requête.
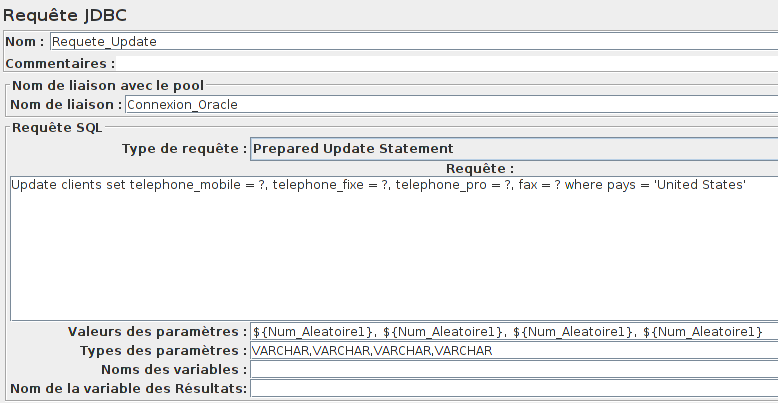
Il est temps de créer notre premier index automatiquement.
Encore une fois, nous utiliserons l'élément Requête JDBC.
La requête SQL de création des index sera directement récupérée à l'aide de la variable ${Create_Index_SQL} du fichier CSV défini précédemment.
Ne pas oublier de mettre à jour les statistiques après la création de l'index.
Pour l'instant il est impossible d'analyser de manière fine le résultat du script, car il nous manque deux informations dans le fichier de résultat de JMeter.
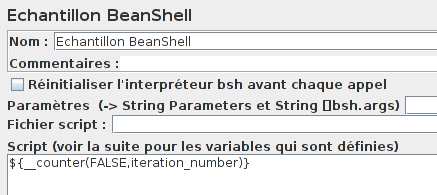
La première information est le nombre d'index qui seront récupérés à l'aide d'un élément Echantillon BeanShell associé à la fonction __counter.
La deuxième information est la requête SQL de création de l'index et elle est déjà dans la variable ${Create_Index_SQL}.
Voilà qui est beaucoup mieux, mais si on récupère un fichier de résultat de l'exécution de notre test, ces deux informations n'y sont pas.
Pour les ajouter, il faut utiliser la propriété sample_variables du fichier properties de JMeter de la manière suivante :
other
2.
3.
4.
# Optional list of JMeter variable names whose values are to be saved in the result data files.
# Use commas to separate the names. For example:
sample_variables=iteration_number,Create_Index_SQL
Ceci conclut notre script de test.
IV-C. Exemple 3 : ETL▲
Dans ce dernier exemple, nous allons utiliser JMeter comme un ETL (Extract Transform Load) pour nous permettre de transférer des données d'une base de données à une autre en y appliquant des transformations.
En particulier on va anonymiser les colonnes nom et telephone_mobile d'une table Clients.
Dans un premier temps, définissons nos connexions aux deux bases de données à l'aide de l'élément Configuration de connexion JDBC.

Afin de générer un nouveau numéro de téléphone, utilisons l'élément Variable aléatoire :
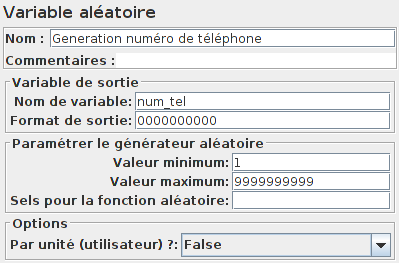
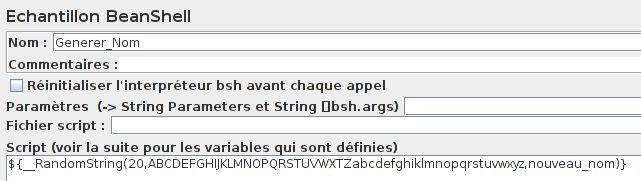
Pour le nouveau nom, nous utiliserons un élément Echantillon BeanShell avec la fonction :
other
${__RandomString(20,ABCDEFGHIJKLMNOPQRSTUVWXTZabcdefghiklmnopqrstuvwxyz,nouveau_nom)}
Un nouveau nom de vingt caractères sera stocké dans la variable nouveau_nom :
Commençons par récupérer les valeurs dans la base de données source (dans notre cas on ne récupérera que certaines colonnes d'une table) à l'aide d'un élément Requête JDBC :
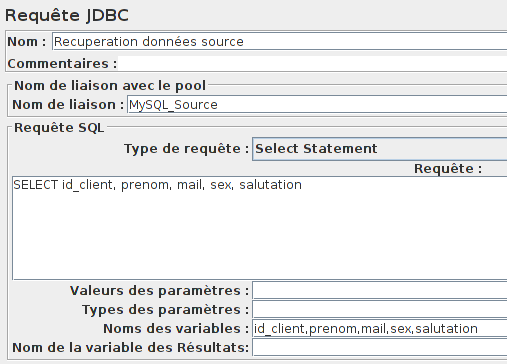
Plusieurs lignes seront récupérées :
other
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
id_client_1=1
id_client_2=2
id_client_3=3
id_client_4=4
...
mail_1=florenceroberts@hotmail.com
mail_2=jennifer_lane@yahoo.com
mail_3=wramos@ldjle.org
...
Maintenant, il faut parcourir chaque ligne récupérée avec l'élément Contrôleur Pour chaque (ForEach).
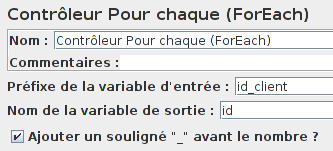
Comme on peut le voir, on ne peut boucler que sur une variable (ici on a choisi id_client), on perd donc le lien avec les autres valeurs de la même ligne (prenom, mail, etc.).
Par exemple, id_client_1 est associé avec prenom_1, mail_1, sex_1 et salutation_1.
Heureusement, on peut facilement recréer le lien entre les variables de la même ligne avec l'élément Compteur et la fonction ${_V(xxx${yyyyy})}
Le compteur va nous permettre de générer un entier incrémenté de 1 à chaque itération de la boucle ForEach (on aura 1, puis 2, puis 3…).
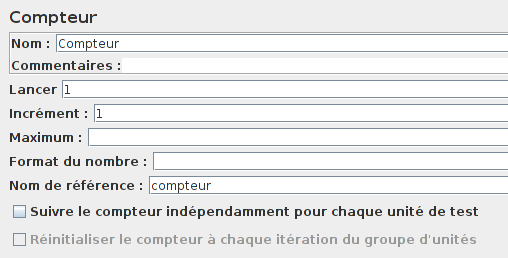
Puis, la fonction ${_V(xxx${yyy})} concaténera la chaîne de caractères xxx_ avec la valeur de la variable yyy.
Par exemple, ${_V(prenom${compteur})} retournera prenom_1 si compteur est égal à un.
Fonction qu'on utilisera dans notre requête SQL d'insertion dans la base de données cible.
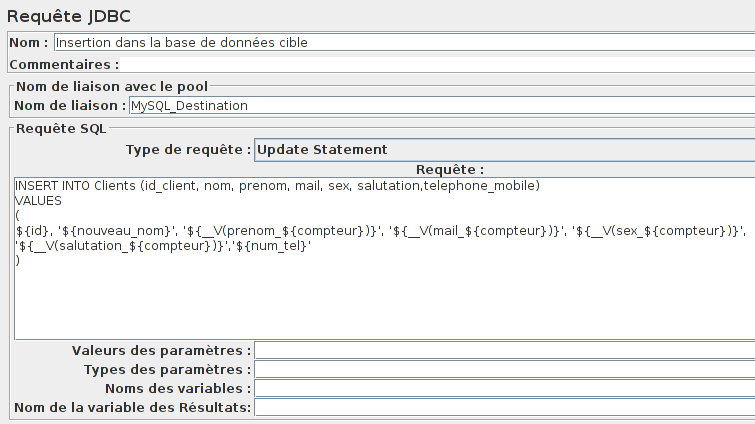
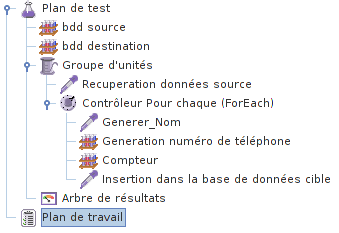
Finalement, notre plan de test ressemblera à celui-ci.
V. Conclusion▲
Comme on a pu le voir, réaliser un test de charge d'une base de données à l'aide de JMeter est possible sans grande difficulté. Les possibilités de JMeter permettent en plus de rendre un test de charge réaliste, de réaliser à peu près tout ce qui vous passe par la tête.
VI. Remerciements▲
Cet article est une œuvre de Antonio Gomes Rodrigues, Bruno Demion et Philippe Mouawad, auteurs du livre Maîtriser JMeter : du test de charge à Devops.
Nous tenons à remercier FRANOUCH pour sa relecture attentive de cet article et Mickael Baron pour la mise au gabarit.